[DACON] 서울시 따릉이 대여량 예측 경진대회

데이터 불러오기

먼저, 'pd.read_csv' 라는 함수를 통해
csv 파일을 불러옵니다.
그 전에 pandas, numpy, matplotlib, seaborn을
import 해주었습니다.
변수 설명
id : 날짜와 시간별 id
hour_bef_temperature : 1시간 전 기온
hour_bef_precipitation : 1시간 전 비 정보
hour_bef_windspeed : 1시간 전 풍속(평균)
hour_bef_humidity : 1시간 전 습도
hour_bef_visibility : 1시간 전 특정 기상 상태에 따른 가시성
hour_bef_ozone : 1시간 전 오존
hour_bef_pm10 : 1시간 전 미세먼지
hour_bef_pm2.5 : 1시간 전 미세먼지
count : 시간에 따른 따릉이 대여 수
현재 예측하고자 하는 것이 따릉이 대여량이므로
count 변수가 종속변수가 되겠고,
나머지 변수들이 독립변수가 되겠습니다.
데이터 시각화

본격적인 데이터 분석 시작에 앞서, heatmap을 통해
각 변수들 간의 상관관계를 알아보았습니다.
* 보통 0.4 이상이면 두 개의 변수간에
상관성이 있다고 얘기합니다.
데이터 분석을 할 때 상관관계 표를 보고
알고자 하는 바를 목차로 적어두면
좋은 것 같습니다.
Q. 어떤 시간대에 따릉이 대여량이 가장 많을까 ?

A. 따릉이 대여량은 오전 8-9시경에 급증하다가
오후 18시 - 19시에 가장 높은 수치를 보였습니다.
이를 통해 예측해보자면 출퇴근 시간대에
대여량이 급증하는 듯 합니다.
Q. 주어진 데이터는 몇 월의 데이터일까 ?

A. 평균기온이 16도인 것으로 보아 5월이라고
예측해볼 수 있습니다.

+ 이렇게 시간대별 모든 변수의 그래프를 그려보았을 때,
온도, 풍속, 오존, 가시성은 거의 비슷한 양상을 보임에 반해
습도는 반대의 그래프를 보였고, 미세먼지 또한 비슷했습니다.


바람과 온도는 습도와 음의 상관관계를 나타냄을
scatter을 통해 알 수 있습니다.
데이터 전처리

먼저 결측치 여부에 대해 파악을 해보겠습니다.
총 1459개의 행으로 통일되어야하는데.
각기 다른 행의 수를 가지고 있음을 알 수 있었습니다.

정확히 각 변수마다 몇 개의 NAN 값을
가지고 있는지 알아보았습니다.
1. 온도 변수 전처리

온도 변수는 2개의 결측치만을 가지고 있습니다.
'isna' 함수를 통해 자정과 오후 6시에 결측치를
가지고 있음을 알 수 있습니다.

하지만 평균으로 결측값을 채우기에는
자정과 오후 6시의 평균 시간이 온도 변수의 평균과
너무나 큰 차이가 존재함을 알 수 있습니다.

이럴 때는 딕셔너리로
자정 결측값엔 자정 시간대의 평균 온도를,
18시 결측값엔 18시 시간대의 평균온도를 넣어줍니다.
2. 풍속변수 전처리

풍속 변수에 있는 결측치들도
시간대별 평균값으로 채워줍니다.

preciptation 변수는 1과 0의 값만 띄므로
전체 값 중에 1과 0의 비율을 파악해본 결과,
대다수가 0이었기에 NAN 값을 0으로 대체해줍니다.
나머지 변수들은 모두 NAN에
해당 변수의 평균값으로 대체하였습니다.
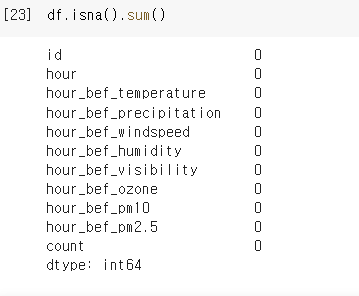
그 결과, NAN이 모두 없어졌음을 알 수 있었습니다.

train 데이터만 해주는 것이 아니라
test 데이터에도 똑같은 전처리를 해주어야합니다.
데이터 모델링

데이터 분석을 하는 데에 있어서
독립변수를 총 3개만 사용하고자 합니다.
train의 독립변수에 위 변수 3개를 넣어주고,
종속변수에는 알고자 하는 대여량 변수를
넣어주면 됩니다.
test 에도 똑같은 작업을 해줍니다.

RandomForest라는 모델을 쓰기위해
import를 해줍니다.
n_estimators는 랜덤포레스트의
나무갯수를 의미합니다.
max_depth는 나무의 깊이를 뜻합니다.
RandomForest 특성상 random한 값이 나오므로
어떠한 환경에서도 같은 값이 나오도록
random state를 고정시켜줍니다.
이러한 옵션을 하이퍼파라미터라고 하는데,
다양한 옵션을 주는 이유는
분석하는 데이터마다 데이터에 적합한
옵션이 다르기 때문입니다.
따라서 다양한 실험을 통해
데이터에 적합한 옵션을 찾아야하는데,
이러한 과정을 '튜닝'이라고 합니다.

각각의 모델별로 fit 함수를 통해
학습을 시켜준 후, 예측을 합니다.

이제 답안지 파일이었던 submission에
각 모델의 예측값을 대입해준 다음
RMSE를 측정해주면 됩니다.
RMSE는 오차이므로
작은 값일수록 높은 성능을 띕니다.