[Machine Learning] 다중 선형 회귀분석 ( 지도학습 / 예측 )

https://piscesue0317.tistory.com/27
[Data Science] 지도학습과 비지도학습이란 ?
데이터 마이닝이란 대량의 데이터를 탐색하고 분석하여 의미 있는 패턴과 규칙을 발견하는 것입니다. 또한, 예측이 주된 목적입니다. 이러한 데이터 마이닝에는 다양한 기법들이 존재합니다.
piscesue0317.tistory.com
지도학습이란 y = f(x) 에 대해
입력변수 (X) 와 출력변수 (Y)의 관계에 대하여 모델링하는 것입니다.
즉, Y에 대해 예측하거나 분류하는 문제를 다룹니다.
https://piscesue0317.tistory.com/34
[Machine Learning] 선형 회귀분석 ( 지도학습 / 예측 )
https://piscesue0317.tistory.com/27 [Data Science] 지도학습과 비지도학습이란 ? 데이터 마이닝이란 대량의 데이터를 탐색하고 분석하여 의미 있는 패턴과 규칙을 발견하는 것입니다. 또한, 예측이 주된 목
piscesue0317.tistory.com
위 글을 통해 선형 회귀분석에
대해 알아보았습니다.
선형 회귀분석이란
하나의 종속변수와 독립변수 간의 관계를 보여주는
통계적 방법입니다.
이때, 독립변수가 하나이면 단순 선형 회귀분석,
둘 이상이면 다중 선형 회귀분석
이라고 합니다.
이 글에서는
'다중 선형 회귀분석'에 대해 알아보고자 합니다.
다중 선형 회귀분석

이는 우리가 단순 선형 회귀분석을 통해
추정해야 하는 식입니다.
단순 선형 회귀분석과 마찬가지로
다중 선형 회귀분석 또한 여러 직선들 중,
직선과 데이터의 차이가 평균적으로 가장 작아지는 직선을 선택합니다.
그럼 어떻게 추정을 하는 것일까요 ?

전체적인 회귀분석의 프로세스입니다.
예시를 통해 다중 선형 회귀분석 방법을
자세히 알아보도록 하겠습니다.

다음과 같은 데이터가 있습니다.
모형 가정
모형 가정 단계는
데이터의 형태를 관찰하여 데이터를 잘 설명할 수 있는
함수 모형을 가정하는 단계입니다.

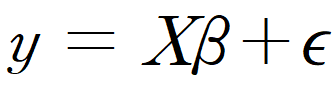
다중 선형 회귀분석에서는
n차식도 회귀 식으로 표현가능 하다는 특징이 있습니다.

위 데이터를 통해 회귀 모형을 가정해 보았습니다.
모형 추정

모형 추정 단계는 모형 가정 단계를 통해 가정한 회귀식에서의
회귀 계수와 절편을 추정해보는 단계입니다.
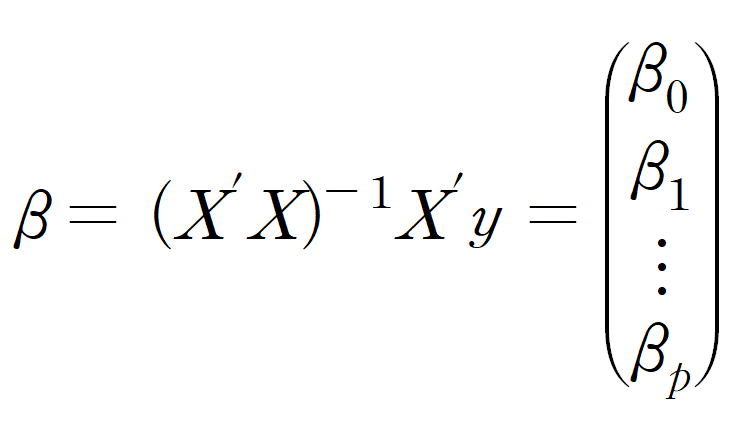
단순 선형 회귀분석과 같이 다중 선형 회귀분석의
회귀계수도 최소제곱법으로 추정합니다.

위 데이터로 추정한 회귀계수입니다.
모형 검토

모형 검토 단계는
추정한 회귀계수를 바탕으로 수립된 모형을
검토하는 단계입니다.
우리는 여기서 총 2가지를 검토합니다.
오차에 대한 가정의 검토
오차는 잔차 Plot을 통해 검토하게 됩니다.
* 선형 회귀 분석의 기본 가정
= 선형성, 독립성, 정규성, 등분산성
1. 독립성 (오차는 서로 독립)

잔차와 관측순서의 Plot이
패턴을 보이지 않으면 오차에 대한 독립성을
만족한다는 의미입니다.
2. 정규성 (오차는 정규분포 형태)

잔차에 대한 정규확률지가
직선을 따르면 정규성을 만족한다는 의미입니다.
3. 등분산성 (오차의 분산이 모두 동일)

특정 패턴을 보이지 않아야
등분산성을 만족합니다.
회귀식의 유의성 검토
분산분석을 통해
최소제곱법에 의해 구한 회귀식이
사용해도 좋을 만큼 유의한 지를 검토합니다.
1. 회귀계수에 대한 가설 세우기

귀무가설을 만족하는 경우 추정된 회귀식은 유의하지 않으며
귀무가설을 기각하는 경우 추정된 회귀식은 유의하다고 판단합니다.
2. 총 제곱합 분해하기

그리고 총 제곱합 (Total Sum of Squares, SSTO) 를
회귀식에 의해 설명되는 변동 (SSR) 과
회귀식에 의해 설명되지 않는 잔차변동 (SSE) 로 분해합니다.
3. 결정계수 파악하기

전체 변동 중 회귀식에 의해 설명되는 변동의 비율인
결정계수가 1에 가까울수록 회귀모형의 유용성이
높다고 판단합니다.
하지만 다중 선형 회귀분석처럼 독립변수의 개수가 증가하면
독립변수가 유의하든, 유의하지 않든 결정계수가 일방적으로 증가하게 됩니다.

이러한 단점을 보완하기 위해 위와 같은 조정된 결정계수를 사용합니다.
조정된 결정계수는 독립변수가 증가할 때 분자를 감소시켜 주어
일방적인 증가를 방지합니다.
4. 분산분석표 F값
| Source of Variation (요인) |
Degree of Freedom (DF, 자유도) |
Sum of Squares (SS, 제곱합) |
Mean Square (MS = SS / DF, 평균) |
| Regression | p | SSR | MSR = SSR / 1 |
| Error | n - p - 1 | SSE | MSE = SSE / n - p - 1 |
| Total | n - 1 | SSTO |
분산분석표에서 나타나는
MSR / MSE = F (검정 통계량)의 값을 보고
가설에 대한 판정을 내립니다.
만약 F값이 F 임계값보다 크면 귀무가설을 기각합니다.
이는 회귀식이 유의하다는 결론을 내릴 수 있음을
의미합니다.
소프트웨어를 이용하면
F값으로 부터 구한 P 값을 유의 수준과 비교하여
판정을 내립니다.