
Anomaly Detection using One-Class Neural Networks

오늘 다뤄볼 논문은 Anomaly Detection과 관련된
'Anomaly Detection using One-Class Neural Networks'라는 논문입니다.
Introduction
본격적으로 논문 내용을 살펴보기 전, 해당 논문에서 중점적으로 다루고 있는
Anomaly Detection(이상탐지)이 무엇인지부터 알아보겠습니다.
위 그림에서도 볼 수 있듯이 대다수의 데이터와 다른 특성을 가지는 데이터를 이상치(Outlier)라고 정의하는데,
이처럼 데이터 중 정상과 이상을 구분하여 이상을 감지하고 식별하는 방법론을 Anomaly Detection이라고 합니다.
이는 사이버 보안, 의학, 금융, 행동 패턴, 자연 과학, 제조업 등 다양한 분야에서 활용됩니다.
이러한 Anomaly Detection에는 다양한 방법론들이 있는데,
정상 및 이상이라는 Label의 유무에 따라 총 세 가지의 방법론으로 분류할 수 있습니다.
1. 지도학습(Supervised Learning) 방법론
지도학습 방법론은 Label을 가진 정상과 이상 데이터를 활용하여 Classification 작업을 수행하는 것입니다.
[장점]
Label 정보가 존재하기 때문에 높은 Detection 성능을 보이고,
결국 분류 문제와 동일해져 분류 모델을 사용할 수 있다는 점에서 모델 선택의 폭이 넓다는 장점을 가지고 있습니다.
[단점]
하지만 Label 정보가 존재한다는 것은 현실적으로 불가능한 경우가 많고,
존재하더라도 Class imbalance 문제가 발생할 수도 있습니다.
2. 준지도학습(Semi-Supervised Learning) 방법론
준지도학습 방법론은 정상 데이터만을 가지고 모델을 학습하여
정상과 다른 패턴의 데이터를 이상으로 탐지하는 방식을 의미합니다.
예시로는 본 논문에서 제시한 방법론과 비교할 모델인 One-Class SVM, 그리고 유사한 Deep SVDD 등이 있습니다.
[장점]
실제로 정상 데이터가 이상 데이터 보다 더 많기 때문에 이상 데이터를 감지하는 데에 본 방법론이 도움이 되므로
가장 현실적인 경우를 가정한 방법론이라고 할 수 있겠습니다.
[단점]
하지만 정상 데이터만을 가지고 학습을 하기 때문에 정상 데이터에 과적합 될 확률이 높아
모델의 성능이 떨어질 수도 있다는 단점이 있습니다.
3. 비지도학습(Unsupervised Learning) 방법론
마지막 비지도 학습 방법론은 대부분의 데이터가 정상 데이터라는 가정을 통해 Label 없이 학습하는 것을 뜻하며
여기에는 PCA와 AutoEncoder 등이 존재합니다.
[장점]
어떠한 경우에서도 사용할 수 있는 방법론이라는 장점이 있습니다.
[단점]
하지만 앞선 두 방법론에 비해 일반적으로 가장 성능이 떨어지고 noise에 민감하다는 단점이 있습니다.
Related Works
이렇게 Anomaly Detection(이상탐지)에 대한 background를 알아보았을 때,
Labeling과 Class imbalance는 해당 분야에 있어 해결되어야 하는 부분이라는 것을 알 수 있습니다.
이러한 점들을 해결하기 위해 해당 논문에서도 다루고 있는 이론인
One-Class Classification(OCC)이 등장하게 되었습니다.
One-Class Classification(OCC)이란 정상, 이상 데이터 사이에 imbalance가 있을 때,
정상 데이터를 정의하는 boundary를 정의하여 이상 데이터를 탐지하는 기법을 의미합니다.
즉 정상 데이터만을 이용해 모델을 학습한 후, 정상 데이터와 거리가 먼 데이터를 이상치로 탐지하는 방법론이므로
앞서 설명드린 세 가지 방법 중 이는 준지도학습 방법론에 해당된다고 말할 수 있겠습니다.
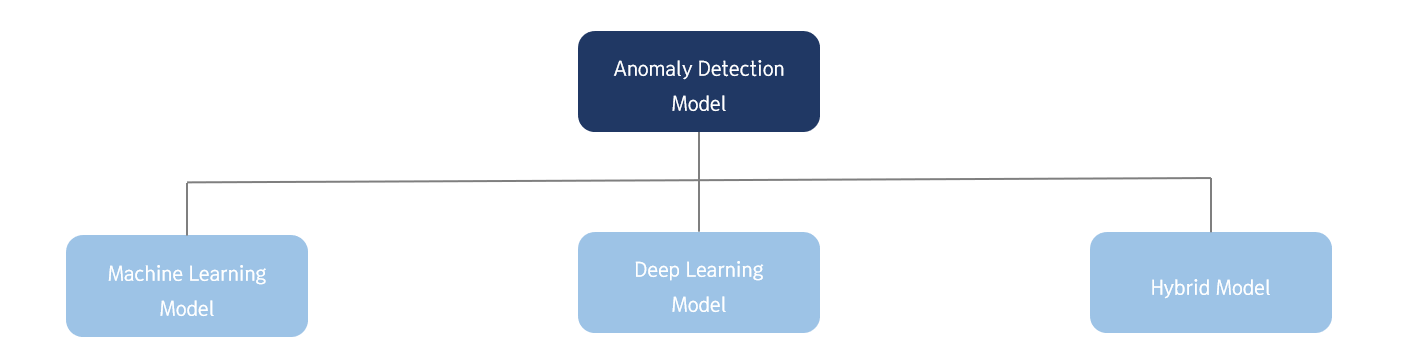
Anomaly Detection 모델은 위 그림처럼 크게 세 가지로 분류할 수 있습니다.
해당 논문이 제안한 모델을 이해하기 위해서는
각각에 해당되는 대표적인 모델의 정보가 필요하므로 간단히 알아보도록 하겠습니다.
1. Machine Learning Model
첫 번째는 비정형 데이터에 대해서는 작동이 불가하지만, 정형 데이터에 대해 준수한 성능을 보이는
Machine Learning 기반의 모델들이며 OC-SVM, Isolation Forest, Clustering 등이 이에 해당됩니다.
[One-Class SVM(OC-SVM)]

One-Class SVM이란, 앞서 설명드렸던 Anomaly Detection의 문제점들 중
Labeling과 Class imbalance를 해소하기 위해 제안된 방법론입니다.
이는 정상 데이터를 원점으로부터 멀리 위치하도록 하고,
정상과 비정상을 구분하는 최적의 초평면을 계산하여 이상탐지를 수행하는 방법론입니다.
즉, 주어진 데이터들을 잘 설명할 수 있는 최적의 support vector를 구하고
이 영역 밖의 데이터들은 outlier로 간주하는 방식입니다.
2. Deep Learning Model
두 번째는 비정형 데이터 및 시계열 데이터에서도 수행이 가능하여 현재 이상 탐지 분야에 많이 활용되고 있는
Deep Learning 기반 모델로 Loss function 설정이 중요한 모델입니다.
[AutoEncoder based Model]

Deep Learning 기반 모델에는 대표적으로 AutoEncoder 계열의 모델이 있습니다.
AutoEncoder란 input layer와 output layer의 node 수가 같고, 하나 이상의 hidden layer로 구성된 encoder를 통해
입력 데이터를 압축한 다음 decoder를 통해 개체를 복원하는 모델을 의미합니다.
AutoEncoder 모델로 이상 탐지를 수행할 때는
AutoEncoder의 Loss function인 Reconstruction error 값이 정상과 이상을 나누는 기준이 됩니다.
예를 들어, 정상인 경우엔 AutoEncoder 모델이 데이터를 더 잘 복원할 것이기 때문에 Reconstruction error 값이 낮고,
이상인 경우엔 높으므로 이러한 방식으로 이상 탐지를 수행합니다.
즉, 복원했을 때 발생하는 복원 오차가 클수록 이상 개체라고 판단하는 방식입니다.
3. Hybrid Model
마지막으로는 본 논문에서도 집중하고 있는 Hybrid 모델입니다.
이는 Deep Learning 기반 모델을 Feature extractor로 활용하여 비정형 데이터에 대해서도
Machine Learning 모델을 적용할 수 있게 한 방법입니다.
예시로는 AutoEncoder 및 Word2Vector 모델을 Machine Learning 모델과 합치는 방법 등이 있습니다.
[Hybrid AutoEncoder]
앞서 설명드린 단일 AutoEncoder와 달리 Hybrid AutoEncoder는 정상 및 이상 데이터의
Reconstruction error 차이가 미미하더라도 AutoEncoder 모델이 둘을 분명히 구분 짓는 feature을 추출할 수 있습니다.
이 경우, encoder가 압축한 input을 다른 Machine Learning 모델의 input으로 사용하면
더 높은 탐지 성능을 기대할 수 있어 Hybrid 모델의 featrue extractor 역할로 AutoEncoder가 사용되는 추세입니다.
Proposed Method

앞서 소개드린 One-Class SVM(OC-SVM)과 AutoEncoder를 결합한 Hybrid 모델에는
각각 문제점이 있다고 본 논문에서는 말하고 있습니다.
OC-SVM Prob.
One-Class SVM은 이상치를 식별하는 데에 널리 사용되는 효과적인 기술이지만
비선형 문제에서는 Kernel trick을 사용하기 때문에 복잡하고 고차원의 데이터셋에서는
계산량이 기하급수적으로 늘어나며 과적합이 발생할 수도 있다는 단점이 있습니다.
Hybrid AutoEncoder Prob.
AutoEncoder를 Feature extractor로 사용한 Hybrid 모델은
AutoEncoder를 통해 feature을 학습하고 해당 feature을 One-Class SVM에 넣어서 검출하게 됩니다.
하지만 AutoEncoder는 기본적으로 데이터를 복원하기 위한 feature을 학습하는 것에 중점을 두는 알고리즘이기 때문에
hidden layer에서 이상과 정상의 차이를 감지하기 위한 feature 학습은 제한적이라는 겁니다.
Sol.
따라서 본 논문에서는 직접 이상 탐지에 특화된 목적함수를 최적화하면서
이상 탐지에 필요한 feature를 더욱 강조할 수 있는 One-Class Neural Network(OC-NN)라는 모델을 제안하였습니다.
또한, 이상 탐지에서는 정상인지 이상인지를 결정하는 최적의 결정 경계를 찾는 것이 중요하므로
본 논문에서 제안한 OC-NN은 OC-SVM과 동일한 역할을 하는 Neural Network 모델이라는 것이 특징입니다.
How?

먼저, 모델이 Original input(입력)의 feature을 얻기 위해 AutoEncoder를 학습시킵니다.
이때, 해당 모델은 One-Class Classification(OCC)을 다루는 준지도학습 방법론이기 때문에
정상 데이터만을 이용해 AutoEncoder을 학습시킵니다.
이렇게 학습된 AutoEncoder에 정상 sample을 넣어주면 입력과 유사한 결과를 복원하게 되고,
정상이 아닌 이상치를 넣게 되면 원본인 이상치가 아닌 학습된 정상 sample이 복원되기 때문에
input과 output의 차이가 커져 이상 탐지가 가능해지는 시스템입니다.
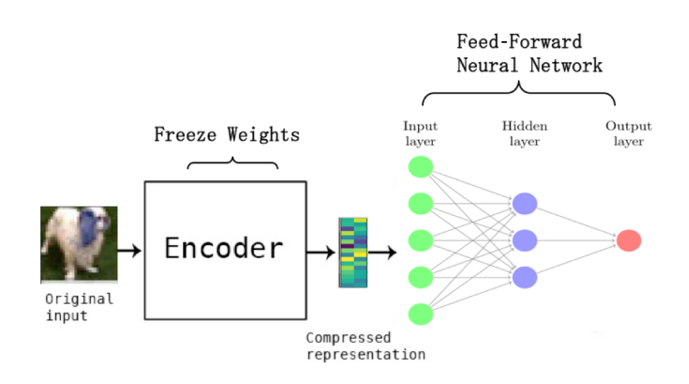
이렇게 학습된 Encoder를 이용하여 Orignal input으로부터 feature을 추출한 뒤,
이를 하나의 hidden layer를 갖는 Feed-Forward Neural Network(FFNN)의 입력으로 이용하여 이상 탐지를 진행합니다.
Feed-Forward Neural Network(FFNN)를 사용함으로써 OC-SVM에서 Kernel trick을 사용한 것처럼
정상과 이상치 간의 결정 경계가 매우 비선형적인 복잡한 데이터셋에서도 구별하는 것이 가능해집니다.
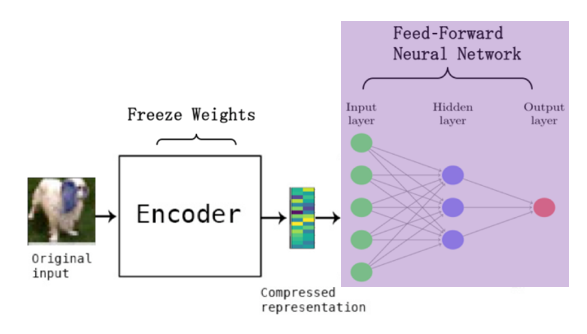
즉, 이 보라색 부분이 OC-SVM을 대체하는 역할로서 Deep Network를 통해 Original input의 feature을 학습하므로
AutoEncoder과 OC-SVM을 결합한 Hybrid 모델보다 이상 탐지에 필요한 feature을
더 잘 학습할 수 있는 부분이라고 할 수 있겠습니다.
또한, FFNN는 OC-SVM의 kernel trick처럼 hidden layer로 비선형 문제를 해결하는데,
이때 OC-SVM에 비해 과도한 계산량과 과적합 문제없이 해결가능하므로
앞선 OC-SVM의 문제를 해결한 방법론이라고 할 수 있겠습니다.
이처럼 해당 모델은 OC-SVM과 같은 목적으로 이상 탐지를 수행하기 때문에 동일한 Loss function을 사용합니다.
1. One-Class SVM Loss Function

그렇다면 OC-NN이 OC-SVM의 Loss function을 어떻게 활용하였는지에 대해 알아보겠습니다.
먼저, OC-SVM의 Loss function은 위와 같습니다.
이는 결정 경계의 가중치 벡터 w와 r에 대한 함수로 해당 함수를 최소화하는 방향으로 최적화를 진행하게 됩니다.
(1)

첫 번째 항은 모델의 변동성 감소를 위한 항으로 즉, 정규화의 역할을 수행하는 항입니다.
data에 따라 변동성이 크면 과적합이 발생하므로 w를 최소화함으로써 이를 방지하고자 하였습니다.
(2)

두 번째 항은 결정 경계와 원점 사이의 거리를 의미하므로 결정경계를 원점으로부터 멀어지게끔 해야
OC-SVM의 이론상 효과적인 이상 탐지가 가능하므로 이를 최소화하고자 하였습니다.
(3)

마지막 항은 결정 경계와 각 데이터 사이의 거리를 나타내는데,
데이터들이 가능한 결정 경계와 가까이 위치하게 하고 결정 경계를 넘어가는 데이터 수를 최소화하고자 하였습니다.
이렇게 총 세 가지 항을 최소화함으로써
이상치를 식별하기 위한 최적의 결정 경계를 찾고자 하는 알고리즘이 OC-SVM입니다.
2. One-Class Neural Network Loss Function

OC-NN의 Loss function을 보면 앞서 설명드린 OC-SVM의 Loss function과 굉장히 비슷한 형태인 것을 볼 수 있습니다.
(1)

OC-NN의 경우도 첫 번째 항을 최소화시킴으로써 과적합을 방지하고자 하였습니다.
(2)

OC-NN은 OC-SVM과 달리 Neural Network 구조이기 때문에
Neural Network의 가중치 V를 가능한 작게만 듦으로써 모델이 더 간단하고 일반화하기 쉬운 형태를 가지도록 하였습니다.
(3)

마지막 항은 Feed-Forward Neural Network(FFNN)의 가중치에 의해 결정된 결정 경계와 data 사이의 거리를 나타내므로
이를 최소화함으로써 이상치를 식별하기 위한 최적의 결정 경계를 찾고자 하였습니다.
One-Class SVM Loss Function vs One-Class Neural Network Loss Function

그렇다면 두 Loss function의 차이점은 무엇일까요 ?
OC-SVM에서는 Original input을 고차원의 feature로 변환시키기 위해 Kernel trick을 사용한 반면,
OC-NN은 Kernel trick을 Sigmoid activation으로 대체한 것을 볼 수 있습니다.
OC-SVM처럼 Kernel trick을 사용하면 계산이 기하급수적으로 늘어나는데,
OC-NN은 Nerual Network를 사용함으로써 이를 방지하고자 하였습니다.
또한, Neural Network는 정상과 이상 데이터 간의 결정 경계가 매우 비선형적인 복잡한 데이터셋에서도
이상 탐지가 가능하므로 OC-NN 모델이 더 효과적인 결과를 얻을 수 있게 됩니다.
본 논문에서는 이렇게 수식이 변화하면서 발생한 효과가 총 3가지라고 언급을 하고 있습니다.
1.
Feed-Forward Neural Network(FFNN)를 사용함으로써 AutoEncoder를 통해 얻은 Original input의 feature를
특정 task를 학습한 모델을 다른 task 수행에 재사용하는 기법인 transfer learning(전이학습)이 가능해졌다고 하였습니다.
2.
Neural Network를 사용하였기 때문에 이상 탐지를 위해 추가적인 layer를 추가하는 것이 가능합니다.
3.

하지만 이렇게 수식이 변화하면서 목적 함수가 non-convex 형태가 되어 global optima를 찾지 못하는 문제가 생기므로
본 논문에서는 따로 알고리즘을 사용함으로써 최적해를 찾고자 하였습니다.
Non-Convex Optimization Algorithm : Alternating Minimization
본 논문에서는 non-convex 목적 함수의 최적점을 찾기 위해 Alternating Minimization 방식을 사용하였습니다.
먼저, 여기서 최적화시키고자 한 변수는 총 3개입니다.
가중치 벡터 w와 행렬 V를 최적화함으로써 예측 오차를 최소화하고, 동시에 모델의 복잡성을 조절하고자 하였습니다.
결정 경계의 bias를 의미하는 r은 값이 작아졌을 때 결정 경계가 정상 데이터에 가까워지고,
값이 커지면 결정경계가 이상 데이터에 가까워지는 변수를 의미합니다.
따라서 본 모델은 OC-SVM과 같은 목적으로 수행되어야 하기 때문에 결정 경계가 정상 데이터에 가까워져야 하므로
r은 이상 탐지 성능을 향상하고자 작아지는 방향으로 최적화하고자 하였습니다.

이렇게 위와 같은 알고리즘으로 앞서 말씀드린 변수 w, V, r의 최적해를 찾고자 하였습니다.
먼저, 결정 경계 함수의 bias인 r을 고정하고 식 (4)를 통해 w와 V에 대한 학습을 진행하였습니다.
그다음 새롭게 정의된 w와 V를 이용해 r을 식 (5)를 통해 학습하였고,
이렇게 번갈아가며 w, V, r을 최적화하는 방식으로 알고리즘을 진행하였습니다.
이때, 해당 알고리즘을 따라가다 보면 r 값이 배열 {yn}에서 뉴배열의 분위수와 동일해진다는 것이 특징입니다.
이게 무슨 뜻일까요 ?

이를 알아보기 위해 배열 {yn}이 1부터 9까지의 수로 이루어져 있고
뉴 값이 0.33일 때를 가정하고 f(r)을 계산해 보겠습니다.
우리는 식 (5)를 통해 함수 f(r)을 최소화하는 r값을 찾는 것이 목표입니다.
따라서 식 (5)를 활용하여 f(r)을 계산하면 맨 오른쪽 열 처럼 계산 값이 도출되고,
목표에 따라 최솟값이 나타내는 지점을 찾으면 되는데 위 예제에서는 그 지점이 r = 3일 때 입니다.
이때, 해당 r값은 배열 {yn}의 0.33 분위수인 3과 동일함을 볼 수 있습니다.
따라서 Alternating Minimization을 통해 구한 목적함수를 최소화하는 r값은
주어진 배열 {yn}의 뉴 분위수라는 의미를 뜻함을 위 증명을 통해 이해할 수 있습니다.
Experiment
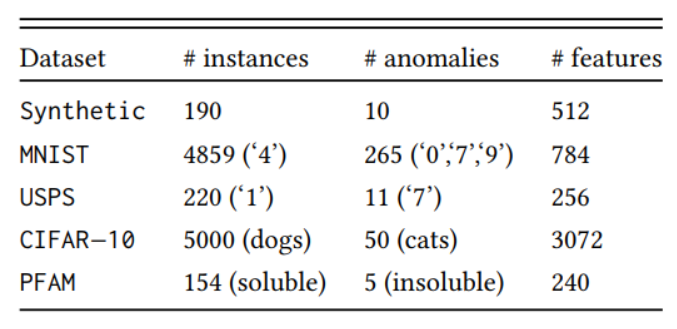
해당 논문은 총 5가지 dataset을 통해 가장 핵심적으로 비교하려고 했던 OC-SVM 모델,
그리고 다른 모델들과도 비교하는 실험을 진행하였습니다.
1. Synthetic data
Syntheic data로 평균은 0, 표준편차를 2로 하여 190개의 정상 sample을 만들고
표준편차를 10으로 하여 10개의 이상 데이터를 생성하여 실험을 진행하였습니다.

위 OC-SVM 그림을 보면 이상치는 음수, 정상은 양수로 분류되어야 올바른 이상 탐지가 이루어지는 것을 알 수 있습니다.

이를 바탕으로 윗줄은 OC-SVM, 아랫줄은 OC-NN의 결과를 의미하는 표를 보시면
이상치의 경우 경계 함수의 값이 음수이므로 OC-NN이 OC-SVM과 유사한 성능을 보인다는 것을 확인하였습니다.
2. MNIST, USPS, CIFAR-10
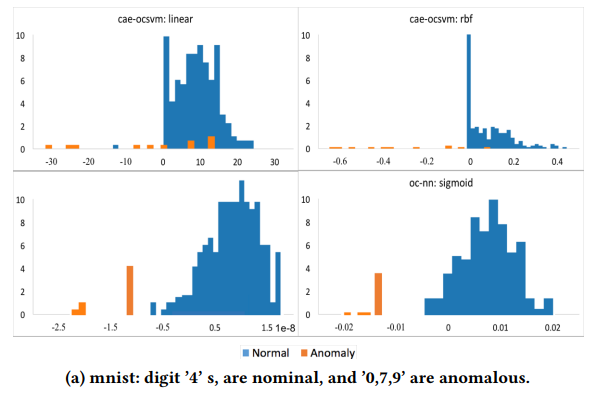


위 3가지 dataset은 이미지 데이터이기 때문에 AutoEncoder를 Convolutional AutoEncoder로 사용하였고,
표를 보시면 OC-NN이 MNIST에서는 OC-SVM보다 성능이 좋고 나머지 dataset에서는 유사함을 알 수 있습니다.
3. PFAM
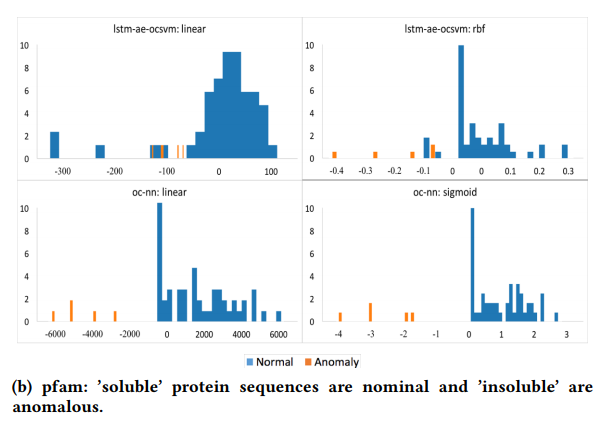
마지막 PFAM이라는 데이터는 154개의 soluble 단백질 배열과 5개의 insoluble 단백질 배열로 되어있는 데이터로서
배열 데이터이기 때문에 LSTM AutoEncoder를 학습에 사용하였고 OC-NN의 성능이 더 좋다는 것을 알 수 있습니다.
최종적으로 OC-SVM과 OC-NN을 비교했을 때, MNIST와 PFAM dataset에서는
OC-NN의 성능이 더 우수함을 확인할 수 있습니다.
4. Etc
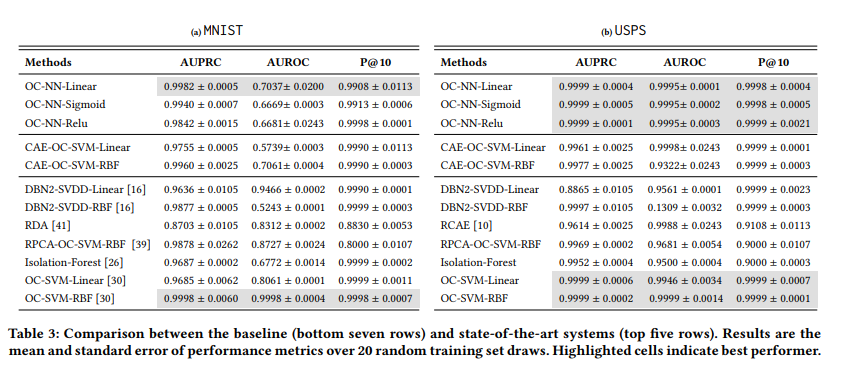
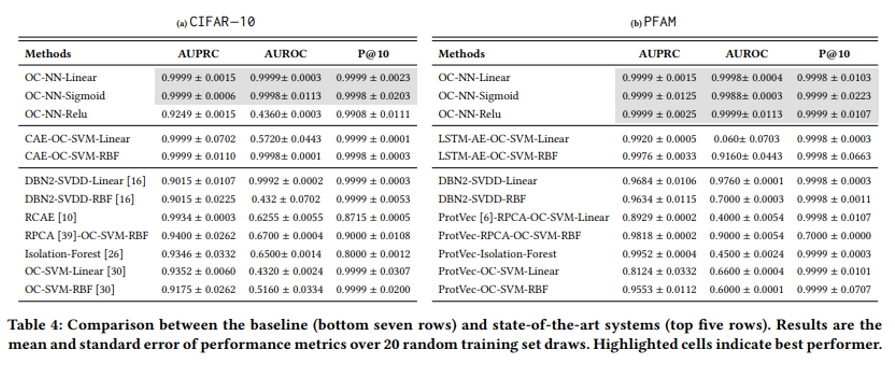
본 논문은 OC-SVM 이외에도 다른 Anomaly Detection 방법론들과도 비교를 하였는데,
결론적으로 OC-NN의 성능이 가장 좋다는 것을 확인할 수 있었습니다.
Conclusion
기존 Hybrid 모델들은 Deep Learning을 오직 Feature extractor로만 사용하였고 이렇게 얻은 feature을 기반으로
Machine Learning 기반 모델들을 학습하여 이상 탐지를 진행하였기 때문에 Deep Learning 모델 자체가
이상 탐지에 유의미한 feature을 학습 및 추출했다고 보기 어려웠습니다.
반면, 제안된 방법론은 학습된 AutoEncoder로 feature을 추출하고
다시 transfer learning(전이 학습)을 통해 재학습시켰기 때문에 Deep Learning 모델이 이상 탐지에
직접적으로 기여가 가능해 목적에 적합한 feature을 학습했다고 볼 수 있는 것이 본 논문의 장점이라고 생각합니다.
하지만 제안된 방법론은 정상 데이터만을 사용하여 학습시켰기 때문에
이는 곧 준지도학습 방법론에 해당된다고 생각이 들었는데, 준지도학습 방법론의 단점인
정상 데이터에서의 과적합 문제를 어떻게 해결하고자 하였는지가 언급되었다면 더 좋았을 것 같다는 생각이 들었습니다.