
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 의사결정나무
- 데이터분석
- 다중선형회귀분석
- LinearRegression
- 시계열데이터
- 손실함수
- dataframe
- 로지스틱회귀분석
- 비지도학습
- ML
- 시계열 데이터
- DataScience
- 지도학습
- LogisticRegression
- 잔차분석
- deeplearning
- 결정계수
- 딥러닝
- 하이퍼파라미터
- RegressionTree
- time series
- GridSearchCV
- 데이터전처리
- 단순선형회귀분석
- machinelearning
- 선형회귀분석
- OrdinalEncoder
- 분류
- Python
- scikitlearn
- Today
- Total
IE가 어른이 되기까지
[Machine Learning] Scikit - Learn을 이용한 데이터 분석 (지도학습 / 예측) 본문

Machine Learning (머신러닝) 이란
기계가 스스로 학습하는 것을 의미합니다.
특히 사람이 지정해준 규칙이나 모델을
스스로 학습하게 됩니다.
https://piscesue0317.tistory.com/27
[Data Science] 지도학습과 비지도학습이란 ?
데이터 마이닝이란 대량의 데이터를 탐색하고 분석하여 의미 있는 패턴과 규칙을 발견하는 것입니다. 또한, 예측이 주된 목적입니다. 이러한 데이터 마이닝에는 다양한 기법들이 존재합니다.
piscesue0317.tistory.com
위 글에서 머신러닝의 종류인
지도학습과 비지도학습에 대해 알아볼 수 있습니다.

이 글에서는 다양한 머신러닝 라이브러리 중
가장 손쉽게 활용할 수 있는 Scikit - Learn에 대해 알아보고자 합니다.
Scikit - Learn은
아래와 같은 다양한 모듈을 제공합니다.
- sklearn.datasets : 내장된 예제 데이터 세트
- sklearn.preprocessing : 다양한 데이터 전처리 기능 제공 (변환, 정규화, 스케일링 등)
- sklearn.pipeline : 묶어서 실행할 수 있는 유틸리티 제공
- sklearn.feature_selection : 특징 (feature) 을 선택할 수 있는 기능 제공
- sklearn.feature_extraction : 특징 (feature) 추출에 사용
- sklearn.model_selection : 교차 검증을 위해 데이터를 학습 / 테스트용으로 분리, 최적 파라미터 추출 (GridSearch)
- sklearn.metrics : 다양한 성능 측정 방법 제공 (Accuracy, Precision, Recall, ROC-AUC, RMSE 등)
* 알고리즘에 필요한 모듈, 클래스, 함수는
각 알고리즘에 따라 별도로 정리되어 있습니다.
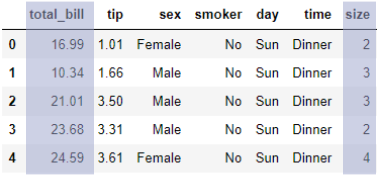
먼저, 지도학습 중 예측을 하기 위한
데이터 분석에 활용할 데이터셋입니다.
기본 패키지 불러오기
import pandas as pd
import numpy as npPandas와 Numpy 라이브러리를 사용하기 위해
불러와줍니다.
데이터 불러오기
tips = pd.read_csv("tips.csv")
'pd.read_csv' 함수를 통해
csv 파일을 불러온 후, 'tips'라는 이름을 가진
DataFrame을 만들어줍니다.
지도학습 중 예측을 목적으로 하는 데이터 분석을 할 때엔
DataFrame에서 예측하고자 하는 y를 찾아야합니다.
위 DataFrame에서는 'tip' 이라는 변수가
우리가 예측하고자 하는 변수이므로 y로 지정을 하고
나머지 변수들은 x로 지정합니다.
데이터 분할 (X, y)
X = tips.drop(['tip'], axis=1) # tip을 제외한 나머지 변수들은 x로 지정
y = tips['tip']
앞서 설명했던 바와 같이
'tip' 을 y로, 'tip' 을 제외한 나머지 변수들은 x로 지정해 줍니다.
이때 '.drop( )'이라는 함수를 사용해서
'tip'이라는 함수를 제거한 것을 'X' 라는 변수에 넣어줍니다.
데이터 분할 (학습데이터, 평가데이터)
과적합을 피하기 위해
데이터를 학습 데이터와 평가 데이터로
분할하도록 하겠습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 1, shuffle=True, stratify = X["size"])
데이터를 분할할 때는 앞서 설명드린 모듈 중 하나인
sklearn.model_selection 중 train_test_split( ) 함수를 사용하도록 하겠습니다.
또한, 본 데이터의 'size' 변수의 비율을 맞춰주기 위해
stratify 옵션을 사용하였습니다.

test_size 라는 옵션을 통해
평가 데이터를 전체 데이터의 0.3로 지정해 주었습니다.
결과적으로 X,y 모두 분할해주었기 때문에
총 4등분으로 나오게 됩니다.
* random_state : 나눠주는 고정값
* shuffle = Ture : 섞어서 나눠주겠다는 의미 (보다 정확해짐)
* stratify : 층을 나눈다는 의미
데이터 전처리 (수치형 변수, 범주형 변수)
전처리를 수행할 때는 수치형 변수와 범주형 변수로
분리하여 수행합니다.
주어진 데이터를 보았을 때
수치형은 total_bill, size이고 범주형은 sex, smoker, day, time
임을 알 수 있습니다.
X_train_num = X_train[["total_bill", "size"]]
X_train_cat = X_train.drop(["total_bill", "size"], axis=1)
# X_train_num = X_train.select_dtypes(include=[np.number])
# X_train_cat = X_train.select_dtypes(exclude=[np.number])
먼저, 수치형과 범주형 변수로 나누어주었습니다.
아래의 방식을 사용해도 됩니다.
보통 전처리 과정은 fit (학습), transform (적용)
이라는 두 단계를 거쳐 적용됩니다.
수치형 변수 전처리
1. 결측치 (NaN) 처리
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median") # 0으로 채우고 싶다면 : ( strategy = "constant".fill_value = 0 )
imputer.fit(X_train_num) # 학습 시키기 : X값에 대해 median이 계산
X_train_num_imputed = imputer.transform(X_train_num) # X_train_num에 값을 실제로 채워서 적용 = transform
# X_num_scaled = scaler.fit_transform(X_num) = 학습과 적용을 한 번에
결측치처리는 Scikit - Learn의 sklearn.impute 모듈의
SimpleImputer 함수를 통해 진행합니다.
이 데이터에 대해서는 결측값을
다양한 통계량 중 median (중앙값) 으로 채워보도록 하겠습니다.
어떠한 값으로 대체할지는 분석가가
데이터의 분포나 패턴, 형태 등을 파악하고 결정하여야 합니다.
그 후, 결측치 처리 과정을
fit을 통해 학습시키고 transform을 통해 적용시킵니다.
만약 학습과 적용을 한 번에 진행하고 싶다면
fit_transform을 실행하면 됩니다.
2. 정규화와 표준화
정규화 혹은 표준화를 통해 Scaling을 해주도록 하겠습니다.
위 데이터에는 두 가지 Scaling 방법 중
정규화를 실행해보도록 하겠습니다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train_num) # 학습 : Min Max Scaler은 min이랑 max를 찾아야함
X_train_num_scaled = scaler.transform(X_train_num) # 적용
정규화 방법은
Scikit - Learn의 sklearn.preprocessning 모듈의
MinMaxScaler 이라는 함수를 사용하여 수행한 후
결측치 처리와 같이 학습 및 적용시킵니다.
범주형 변수 전처리

데이터 분석을 할 때
범주형 데이터는 분석 단계에서 계산이 어렵기 때문에
숫자형으로 변경을 해주어야 합니다.
1. 결측치 (NaN) 처리
from sklearn.impute import SimpleImputer
imputer_cat = SimpleImputer(strategy="most_frequent") # 최빈값
imputer_cat.fit(X_train_cat)
X_train_cat_imputed = imputer_cat.transform(X_train_cat)
# X_train_cat_imputed = imputer.fit_transform(X_train_cat)
수치형 변수와 마찬가지로 범주형 변수도
똑같이 결측치 처리를 해주겠습니다.
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
X_train_cat_encoded = ordinal_encoder.fit_transform(X_train_cat)
Ordinal Encoder 방법은
sklearn.preprocessing 모듈의 Ordinal Encoder 함수를
사용합니다.
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder(sparse=False, drop='if_binary') # sparse = False : 매트릭스 형태로 안나오게 하기 위해서 (압축된 형태로)
X_train_cat_1hot = cat_encoder.fit_transform(X_train_cat)
print(X_train_cat_1hot.shape)
OneHotEncoder 방법은
sklearn.preprocessing 모듈의 OneHotEncoder 함수를
사용합니다.
전처리 과정까지 마쳤다면
해당 데이터셋에 적절한 알고리즘을 선택하여
모델을 생성하고 평가하게 됩니다.
* 모델링 과정은 각 알고리즘에 따라 별도로 정리되어 있습니다.
'ML > Python' 카테고리의 다른 글
| [Machine Learning] 의사결정나무 (CART) Scikit Learn으로 구현하기 (0) | 2023.01.12 |
|---|---|
| [Machine Learning] 회귀분석 Scikit Learn으로 구현하기 (0) | 2023.01.09 |
| [Machine Learning] Scikit - Learn을 이용한 데이터 분석 (비지도학습) (0) | 2023.01.06 |
| [Machine Learning] Scikit - Learn을 이용한 데이터 분석 (지도학습 / 분류) (0) | 2023.01.05 |
| [DACON] 서울시 따릉이 대여량 예측 경진대회 (0) | 2022.12.26 |



