
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 의사결정나무
- machinelearning
- 분류
- LinearRegression
- 손실함수
- 비지도학습
- 로지스틱회귀분석
- 딥러닝
- 시계열 데이터
- OrdinalEncoder
- 단순선형회귀분석
- scikitlearn
- ML
- 데이터전처리
- 지도학습
- LogisticRegression
- Python
- RegressionTree
- 다중선형회귀분석
- DataScience
- 하이퍼파라미터
- 시계열데이터
- dataframe
- deeplearning
- 잔차분석
- 선형회귀분석
- GridSearchCV
- 데이터분석
- 결정계수
- time series
- Today
- Total
IE가 어른이 되기까지
[Machine Learning] 주성분분석 Scikit Learn으로 구현하기 본문

https://piscesue0317.tistory.com/51
[Machine Learning] 주성분 분석 (비지도학습 / 데이터 축소)
만약 예측 시 필요한 독립변수 간 편차가 다르면 어떻게 해야할까요 ? 이런 경우, 각 독립변수에 적절한 가중치를 반영하여 유용한 변수를 생성할 수 있습니다. 이것이 바로 이 글에서 다루고자
piscesue0317.tistory.com
먼저, 위 글은 주성분분석에 대한
이론을 설명하고 있습니다.
https://piscesue0317.tistory.com/32
[Machine Learning] Scikit - Learn을 이용한 데이터 분석 (지도학습 / 분류)
Machine Learning (머신러닝) 이란 기계가 스스로 학습하는 것을 의미합니다. 특히 사람이 지정해준 규칙이나 모델을 스스로 학습하게 됩니다. https://piscesue0317.tistory.com/27 [Data Science] 지도학습과 비지
piscesue0317.tistory.com
또한, 위 글은 본 알고리즘 모델링을
하기 이전의 과정입니다.
해당 과정을 수행하여야 앞으로 진행되는
모델링이 가능합니다.
Scikit - Learn에서는 모델 선택과 훈련을 시킬 때
fit (학습)과 predict (적용) 의 순서를 따릅니다.
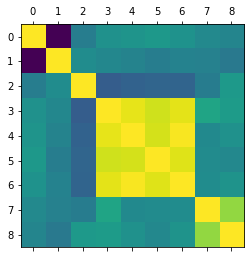
원변수 상관관계 분석
import matplotlib.pyplot as plt
plt.matshow(X.corr())
plt.show()
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10,8))
sns.heatmap(housing.corr(),annot=True)

원 변수의 상관관계를 출력해본 결과
변수들 간 상관관계가 존재함을 알 수 있습니다.
특히 꽤나 높은 상관관계를 보이는 변수들도 있기에
다중공선성과 같은 위험을 방지해주는 주성분 분석을 수행해보도록 하겠습니다.
모델 선택, 학습, 적용
from sklearn.decomposition import PCA
# 1. Define
pca = PCA(n_components=9)
# 2. Fit (학습)
pca.fit(X)
# 3. Transform (적용)
X_pc = pca.transform(X)
# 주성분값을 DataFrame으로 변경
X_pc_df = pd.DataFrame(X_pc)
display(X_pc_df)
# 주성분별 분산의 비율
display(pca.explained_variance_ratio_)
sklearn.decomposition 모듈에서
PCA를 호출합니다.
주성분별 분산의 누적 비율을 살펴본 결과,
제 1주성분의 설명력이 99%인 것을 확인해볼 수 있습니다.
이런 경우, 위 개념 설명에 의하면
주성분의 개수를 1로만 지정할 수 있겠습니다.
주성분간 상관관계 분석
import matplotlib.pyplot as plt
plt.matshow(pd.DataFrame(X_pc_df).corr())
plt.show()
주성분 분석을 실행한 후,
주성분 간 상관관계를 시각화해본 결과 상관관계가 0임을 알 수 있습니다.
'ML > Python' 카테고리의 다른 글
| [Machine Learning] 군집분석 Scikit Learn으로 구현하기 (0) | 2023.02.13 |
|---|---|
| [Machine Learning] 로지스틱 회귀분석 Scikit Learn으로 구현하기 (0) | 2023.01.17 |
| [Machine Learning] KNN Scikit Learn으로 구현하기 (0) | 2023.01.12 |
| [Machine Learning] 의사결정나무 (CART) Scikit Learn으로 구현하기 (0) | 2023.01.12 |
| [Machine Learning] 회귀분석 Scikit Learn으로 구현하기 (0) | 2023.01.09 |



