
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 다중선형회귀분석
- 데이터전처리
- 하이퍼파라미터
- RegressionTree
- LinearRegression
- 분류
- 의사결정나무
- LogisticRegression
- 결정계수
- 시계열데이터
- dataframe
- 선형회귀분석
- 데이터분석
- 손실함수
- 지도학습
- ML
- OrdinalEncoder
- 딥러닝
- Python
- DataScience
- time series
- 비지도학습
- 잔차분석
- machinelearning
- 로지스틱회귀분석
- GridSearchCV
- scikitlearn
- 시계열 데이터
- deeplearning
- 단순선형회귀분석
- Today
- Total
IE가 어른이 되기까지
[Deep Learning] Generative Adversarial Network (GAN) 본문

이번 글에선 GAN에 대해 알아보겠습니다.
GAN이란 ?
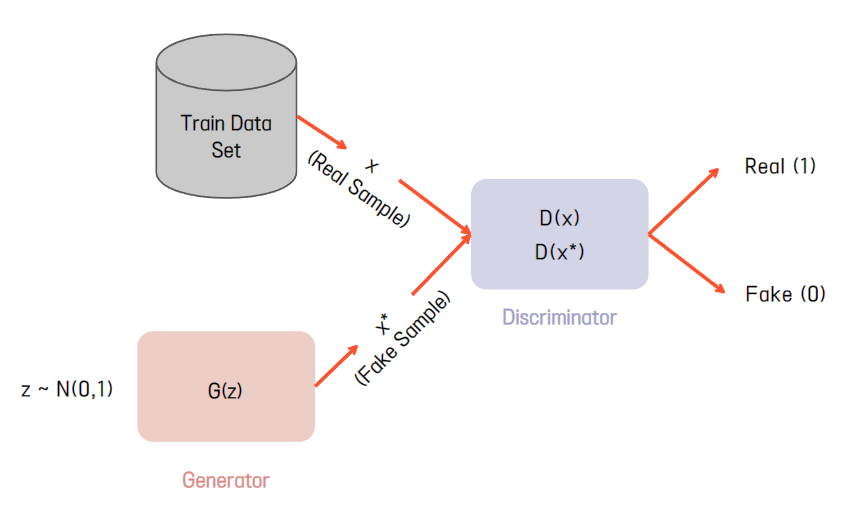
Generative Adversarial Networks (GAN) 는
가상의 data를 만들어내는 Generator와 그렇게 만들어진 data를 평가하는 Discriminator가
서로 대립적(Adversarial)으로 경쟁하며 성능을 점차 개선해나가는 알고리즘입니다.

즉, Generate는 위조 지폐를 생성해내는 위조지폐범이고
Discriminator은 그런 위조지폐범을 검거하려하는 경찰인 셈입니다.
위조지폐범은 더 진짜 같은 위조 지폐를 만들기 위해 점점 노력할 것이고,
경찰은 그들의 수법과 실제 지폐를 공부함으로써 그들을 잡으려 노력할 것입니다.
이것이 GAN입니다.
GAN의 손실함수

GAN의 손실함수에 대해 알아보겠습니다.
* D(x) : Discriminator(D)가 진짜라고 할 확률
G(z) : 생성된 이미지
x : 실제 데이터
z : 랜덤 노이즈
1. Generator

이처럼 D(G(z))가 1에 가까운 값이 되면
손실함수가 줄어듭니다.
2. Discriminator

Discriminator가 실제 데이터를 실제로 판별하고,
가짜 데이터는 가짜로 판단해야 한다는 의미입니다.
이처럼 Generator와 Discriminator은 서로 경쟁하며 학습해나아갑니다.
예시

노란색으로 보이는 이미지들은
모두 실제가 아닌 가상의 이미지들입니다.
GAN의 한계점
1. 성능평가 방법 부재
- GAN 모델의 결과는 새롭게 만들어진 데이터이기 때문에 비교 가능한 정량적 척도가 없어 모델의 성능을 객관적 수치로 표현할 수 있는 방법 부재
2. 성능 불안정
- GAN은 기존 Network 학습 방법과 다른 구조여서 학습이 불안정
3. Mode Collapse
- 변환된 데이터의 분포가 특정 형태에 치우치는 문제
- 예를 들어, MNIST 데이터로 학습하여 데이터를 생성하는 경우, Generator가 한 숫자만 생성하여 Discriminator를 지속적으로 속이는 현상 (목적함수에는 전혀 어긋나지 않음)
'DL > Algorithms' 카테고리의 다른 글
| [Deep Learning] Convolutional Neural Network (CNN) (0) | 2023.02.28 |
|---|---|
| [Deep Learning] AutoEncoder (AE) (0) | 2023.02.17 |
| [Deep Learning] 딥러닝이란 ? (0) | 2023.02.15 |


