
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 로지스틱회귀분석
- 하이퍼파라미터
- 데이터전처리
- DataScience
- ML
- dataframe
- deeplearning
- 비지도학습
- 시계열 데이터
- OrdinalEncoder
- 단순선형회귀분석
- RegressionTree
- 잔차분석
- LinearRegression
- 시계열데이터
- Python
- 손실함수
- time series
- 분류
- LogisticRegression
- 선형회귀분석
- 다중선형회귀분석
- 결정계수
- GridSearchCV
- machinelearning
- 데이터분석
- 의사결정나무
- scikitlearn
- 지도학습
- 딥러닝
- Today
- Total
IE가 어른이 되기까지
[Deep Learning] Keras로 예측 / 분류 모델 만들기 본문

https://piscesue0317.tistory.com/53
[Deep Learning] 딥러닝이란 ?
기계학습이란 주어진 데이터를 바탕으로 지식을 자동으로 습득하여 스스로 성능을 향상하도록 하는 기술입니다. 데이터를 기반으로 모델을 자동으로 생성한 후, 규칙이나 패턴을 발견하여 미
piscesue0317.tistory.com
이전 글에서 딥러닝에 관한 이론을 다루었습니다.
이번 글에서는 머신러닝에서 하던 예측과 분류를
딥러닝으로 학습해보겠습니다.
!pip install tensorflow
다양한 딥러닝 라이브러리 중
keras를 사용하기 위해 tensorflow를 설치해줍니다.
1. 예측 (Regression)
필요한 라이브러리 import
import pandas as pd
import numpy as np
import tensorflow as tf
from keras import layers, models
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import TensorBoard
from time import time
먼저 학습 모델링에 있어
필요한 라이브러리를 불러옵니다.
데이터 불러오기
dataset = pd.read_csv('diamond.csv')
dataset.head()
예측하고자 하는 데이터를
불러옵니다.
데이터 전처리 (One-Hot Encoding)
data = pd.get_dummies(dataset)
data.head()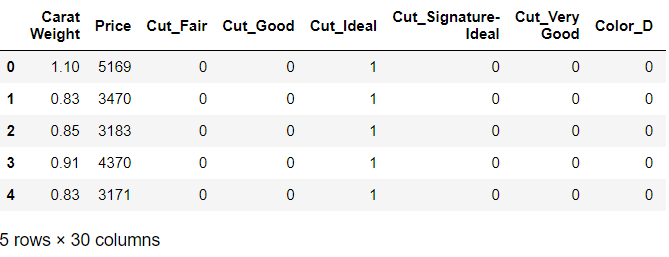
독립변수가 범주형이기 때문에
One-Hot Encoding을 통해 전처리를 해줍니다.
데이터 분할하기
X = data.drop(['Price'], axis=1)
y = data['Price']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
예측하고자 하는 'Price'를 y로
나머지 독립변수들을 x로 지정해줍니다.
Scikit-Learn에 포함되어있는
train_test_split을 불러와 train과 test로 데이터를 분할해줍니다.
모델 구성하기
X_train.shape
input_node = 29
hidden_node = [64, 64, 32]
output_node = 1
model = Sequential() # 총 4층짜리 모델 생성
model.add(Dense(hidden_node[0], activation = 'relu', name = 'Hidden1',
input_dim = input_node, kernel_initializer='random_uniform', bias_initializer='zeros'))
model.add(Dense(hidden_node[1], activation = 'relu', name = 'Hidden2'))
model.add(Dense(hidden_node[2], activation = 'linear', name = 'Hidden3'))
model.add(Dense(output_node))
# hidden_node[?] : 초기에 hidden node 수를 정해준 list 안에서 순서대로 가지고옴
# ex) hidden_node[0] = 64를 의미
# activation : 활성함수
# kernel_initializer = 'random_uniform" : 가중치를 -0.05~0.05로 균등하게 작은 임의의 값으로 초기화
# bias_initializer : 절편 초기화 시키기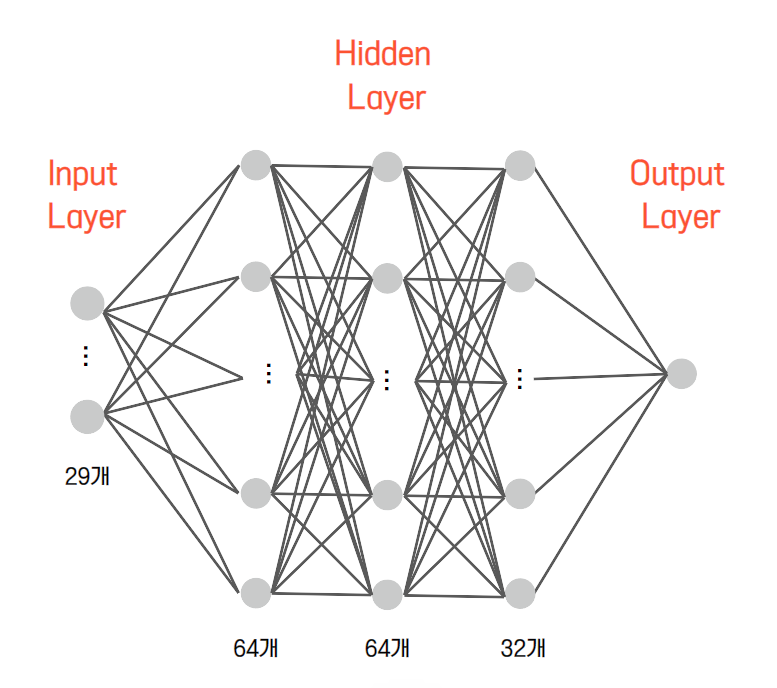
모델을 그림으로 표현하면 위와 같습니다.
이때, 그림에 나타난 원을 'node'라고 정의합니다.
hidden node의 개수는 임의로 결정할 수 있지만,
input node의 개수는 독립변수의 개수여야하며 output node의 개수는
종속변수의 개수와 동일해야합니다.
node의 개수를 정해주었으면
model.add를 통해 인공신경망을 구성해줍니다.
Dense는 모델 Layer의 구성을 의미하며
초기에 지정해주었던 Layer 별 노드의 수와 활성함수 등을 지정해줍니다.
모델 학습과정 설정하기
model.compile(loss = 'MSE', optimizer = 'adam', metrics = ['mae', 'mse'])
모델의 Loss Function (손실함수) ,
즉 예측값과 실제값간의 차이를 MSE로 계산합니다.
또한, 이 Loss를 최소화하기 위해
필요한 최적화 방법론들 중 'Adam'을 선택합니다.
모델 학습시키기
model.fit(X_train, y_train, epochs = 28, batch_size = 10, validation_split = 0.3)
model.fit을 통해 모델을 학습시킵니다.
학습할 X와 y training 데이터셋을 불러와줍니다.
이때, epochs는 Loss (손실함수) 를 줄이기 위해 반복 학습할 수를 지정해주고,
batch size는 데이터를 몇 개씩 묶어서 학습할 것인지 지정해줍니다.
예를 들어, batch size가 10이면
10개의 데이터를 묶어 학습할때마다 실제값과 비교해보며
가중치 업데이트가 일어납니다.
모델 평가하기
result = model.evaluate(X_test, y_test, batch_size = 10)
print('Test Loss and MAE/MSE : ', result)
y_pred = model.predict(X_test)from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
MAE = mean_absolute_error(y_test, y_pred)
MSE = mean_squared_error(y_test, y_pred)
MAPE = mean_absolute_percentage_error(y_test, y_pred)
print("MAE :", MAE, "MSE :", MSE, "MAPE :", MAPE)
model.evaluate를 통해 모델을 평가합니다.
X_test를 기반으로 y를 예측한 후,
실제 y와 비교함으로써 모델을 평가합니다.
2. 분류 (Classification)
필요한 라이브러리 import
import pandas as pd
import numpy as np
import tensorflow as tf
from keras import layers, models
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import TensorBoard
from time import time
필요한 라이브러리를 불러와줍니다.
데이터 불러오기
dataset = pd.read_csv('iris.csv')
dataset.head()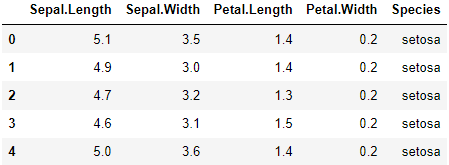
모델에 사용하고자하는 데이터를
불러옵니다.
dataset['Species'].value_counts()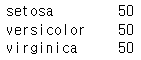
위 코드를 통해 종속변수의 종류는
3개임을 알 수 있습니다.
데이터 분할하기
X = dataset.drop(['Species'], axis=1)
y = dataset['Species']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
분류하고자 하는 'Species' 종속변수를 y로 지정하고,
나머지 독립변수들은 x로 지정해줍니다.
또한, Scikit-Learn에 포함되어있는 train_test_split를 통해
데이터를 train, test로 분할해줍니다.
데이터 전처리 (Label Encoder, One-Hot Encoding)
from sklearn.preprocessing import LabelEncoder
# 1. define
LE = LabelEncoder()
# 2. fitting
LE.fit(y_train)
# 3. transform
y_train = LE.transform(y_train)
y_test = LE.transform(y_test)from keras.utils import np_utils
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
DataFrame에 의하면 종속변수는 범주형입니다.
따라서 'LabelEncoder'을 통해 범주형 변수의 문자열을 수치형으로 변환해줍니다.
그 후, 다시 'One-Hot Encoding'을 통해
1과 0으로 표현해줍니다.
모델 구성하기
input_node = 4
hidden_node = [10, 10]
output_node = 3
model = Sequential()
model.add(Dense(hidden_node[0], activation = 'relu', name = 'Hidden1',
input_dim = input_node, kernel_initializer='random_uniform', bias_initializer='zeros'))
model.add(Dense(hidden_node[1], activation = 'relu', name = 'Hidden2'))
model.add(Dense(output_node, activation = 'softmax'))
독립변수는 4개이므로 input node는 4개,
종속변수의 종류는 총 3개이므로 output node는 3개입니다.
model.add를 통해 인공신경망의 Layer를
총 3층으로 쌓고 지정한 hidden node의 수와 활성함수 등을 모델링 해줍니다.
모델 학습과정 설정하기
model.compile(loss = 'categorical_crossentropy', optimizer = 'Adam', metrics = 'accuracy')
딥러닝 이론에서도 언급했다시피 model.compile을 통해
분류 문제에서는 'crossentropy'라는 Loss (손실함수) 를 사용합니다.
이러한 손실함수를 최소화하기 위한 최적화 방법론으로는
'adam'을 지정해주며 정확도를 통해 모델을 평가하고자 합니다.
모델 학습시키기
model.fit(X_train, y_train, epochs = 100, batch_size = 10, validation_split = 0.3)
Regression 문제에서도 봤다시피
모델을 위와 같이 model.fit을 통해 학습시켜줍니다.
모델 평가하기
result = model.evaluate(X_test, y_test, batch_size = 10)
print('Test Loss and Accuracy : ', result)
y_pred = model.predict(X_test)
print(y_pred)
model.evalutae을 통해 모델을 평가합니다.
from sklearn.metrics import confusion_matrix
matrix = confusion_matrix(y_test.argmax(axis=1), y_pred.argmax(axis=1))
matrix
Confusion Matrix를 통해
잘 분류되었는지 볼 수 있습니다.
# prediction
y_test_real = y_test.argmax(axis=1) # 해당 배열의 최대값 : 실제
y_test_hat = y_pred.argmax(axis=1) # 해당 배열의 최대값 : 예측
# MAE / MSE
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
accuacy = accuracy_score(y_test_real, y_test_hat)
precision = precision_score(y_test_real, y_test_hat, average = "micro")
recall = recall_score(y_test_real, y_test_hat, average = "micro")
f1 = f1_score(y_test_real, y_test_hat, average = "micro")
print("Accuracy :", accuacy.round(2), "precision :", precision.round(2), "Recall :", recall.round(2), "F1 :", f1.round(2) )
마지막으로 정확도, 재현율, 정밀성, f1-score을 통해
모델의 성능을 확인합니다.
'DL > Python' 카테고리의 다른 글
| [Deep Learning] AE Keras로 구현하기 (0) | 2023.02.17 |
|---|
