
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 분류
- 비지도학습
- 시계열 데이터
- machinelearning
- 잔차분석
- 데이터분석
- LogisticRegression
- GridSearchCV
- 단순선형회귀분석
- 결정계수
- LinearRegression
- time series
- ML
- Python
- scikitlearn
- 시계열데이터
- dataframe
- 지도학습
- OrdinalEncoder
- 손실함수
- 딥러닝
- 로지스틱회귀분석
- 선형회귀분석
- RegressionTree
- 하이퍼파라미터
- deeplearning
- 의사결정나무
- DataScience
- 다중선형회귀분석
- 데이터전처리
- Today
- Total
IE가 어른이 되기까지
[Deep Learning] AE Keras로 구현하기 본문

https://piscesue0317.tistory.com/55
[Deep Learning] AutoEncoder 이란 ?
AutoEncoder은 비교사학습을 위한 딥러닝입니다. 이번 글에서는 AutoEncoder에 대해 알아보도록 하겠습니다. * 비교사학습 : Output이 존재하지 않는 학습 AutoEncoder이란 ? AutoEncoder은 Input과 Output을 동일하
piscesue0317.tistory.com
위는 AutoEncoder에 대한 이론입니다.
필요한 라이브러리 import
import numpy as np
from keras.datasets import mnist
from keras.layers import Dense, Input
from keras.models import Model
import matplotlib.pyplot as plt
from keras import layers, models
from keras.models import Sequential
from keras.callbacks import TensorBoard
from time import time
AutoEncoder를 구현하기 위해
필요한 라이브러리를 불러옵니다.
데이터 불러오기
(X_train, y_train), (X_test, y_test) = mnist.load_data()

keras에는 'mnist' 데이터가 존재합니다.
'mnist'는 0부터 9까지의 숫자에 대한 손글씨 이미지 데이터입니다.
이는 28X28 이미지 데이터입니다.
이 글에서는 'mnist' 이미지 데이터를 활용하여 AutoEncoder를
구현해보고자 합니다.
데이터 정규화 및 재구성
# 정규화
X_train = X_train / 255.
X_test = X_test / 255.
# 데이터 재구성
X_train = X_train.reshape(-1, 28*28)
X_test = X_test.reshape(-1, 28*28)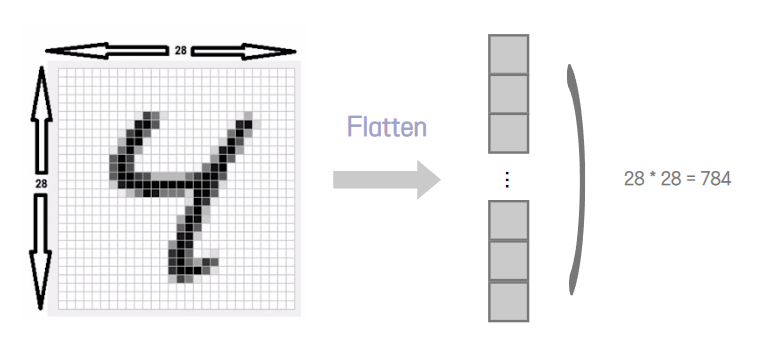
AutoEncoder 형태로 만들기 위해서는
픽셀을 곱하는 Flatten 과정을 거쳐 벡터의 형태로 표현해줘야합니다.
모델 구성하기
input_node = 28 * 28
hidden_node = [128, 64, 32]
encoder = Sequential()
encoder.add(Dense(hidden_node[0], activation='relu', input_dim=input_node))
encoder.add(Dense(hidden_node[1], activation='relu'))
encoder.add(Dense(hidden_node[2], activation='relu'))
decoder = Sequential()
decoder.add(Dense(hidden_node[1], activation='relu', input_dim=hidden_node[2]))
decoder.add(Dense(hidden_node[0], activation='relu'))
decoder.add(Dense(input_node, activation='sigmoid'))
model = Sequential([encoder, decoder])
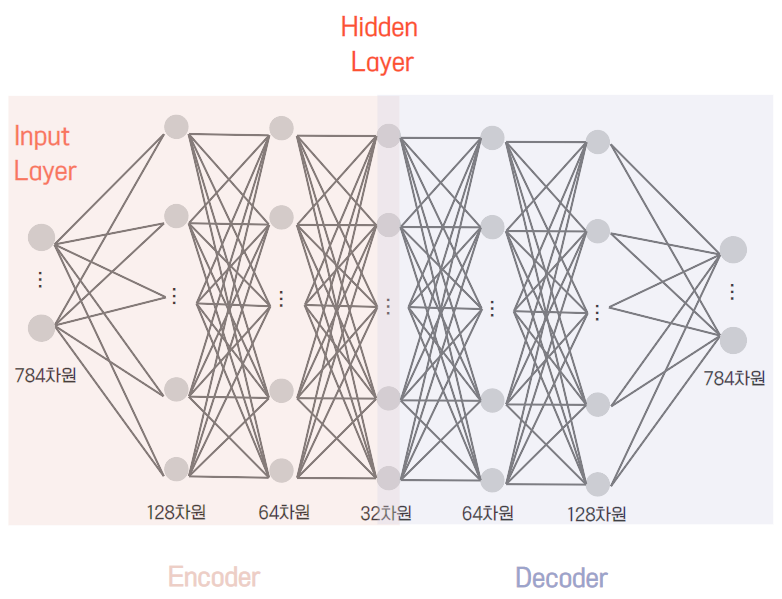
.add 함수를 통해 모델을 구성합니다.
특히 AutoEncoder은 Encoder와 Decoder의 모델을 각각 생성합니다.
input node는 이미지 픽셀을 flatten 시켰기 때문에 784차원이 되며
비지도 학습이므로 output node는 존재하지 않습니다.
또한, Encoder은 128, 63, 32를 지나면서 32차원이 되며
Decoder은 32차원에서 다시 784차원이 되는 것을 알 수 있습니다.
모델 학습과정 설정하기
model.compile(loss = "mse", optimizer = 'adam', metrics = ['mae', 'mse'])
model.compile을 통해 모델 학습 과정을 설정합니다.
AutoEncoder의 Loss Function (손실함수) 은 MSE로 설정하고,
손실함수를 최소화시킬 최적화 방법은 'adam'으로 설정합니다.
모델 학습시키기
model.fit(X_train, X_train, epochs = 30, batch_size = 100, validation_data = (X_test, X_test))
AutoEncoder에서는 input도 X_train, output도 X_train으로
설정하여 실제값이 복원되도록 합니다.
model.fit을 통해 epoch와 batchsize를 정해줍니다.
예측하기
encoded_imgs = encoder.predict(X_test)
decoded_imgs = decoder.predict(encoded_imgs)
print(X_test.shape)
print(encoded_imgs.shape)
print(decoded_imgs.shape)
input (원 이미지 데이터) 인 784차원으로 모델을 검증합니다.
즉, decoder을 통해 나온 784차원의 이미지가 input과
얼마나 일치하는지를 확인합니다.
시각화
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(X_test[i].reshape(28, 28), cmap = "gray")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28), cmap = "gray")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
잘 복원됐는지 확인하기 위해
Decoder를 통과한 마지막 이미지 데이터들을 시각화해보았습니다.
X_test 와 비교해본 결과 꽤나 잘 복원되었음을 볼 수 있습니다.
'DL > Python' 카테고리의 다른 글
| [Deep Learning] Keras로 예측 / 분류 모델 만들기 (0) | 2023.02.17 |
|---|
