
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- machinelearning
- 시계열 데이터
- 로지스틱회귀분석
- RegressionTree
- 지도학습
- time series
- 분류
- 비지도학습
- 데이터전처리
- Python
- 단순선형회귀분석
- 딥러닝
- LogisticRegression
- GridSearchCV
- 데이터분석
- 의사결정나무
- 손실함수
- 하이퍼파라미터
- 결정계수
- 시계열데이터
- dataframe
- DataScience
- LinearRegression
- ML
- 잔차분석
- scikitlearn
- deeplearning
- 선형회귀분석
- OrdinalEncoder
- 다중선형회귀분석
- Today
- Total
IE가 어른이 되기까지
Collective Decision of One-vs-Rest Networks for Open Set Recognition 본문
Collective Decision of One-vs-Rest Networks for Open Set Recognition
기모랑의 초코 2023. 8. 8. 19:50

이번 글에서 다뤄볼 논문은 Open Set Recognition과 관련된
'Collective Decision of One-vs-Rest Networks for Open Set Recognition'이라는 논문입니다.
Introduction
먼저, 해당 논문에서 제시한 방법론이 어떠한 배경에 의해 등장하게 되었는지부터 알아보겠습니다.
Prob.

예를 들어, training data set에 강아지, 고양이 이미지가 있을 때
우리는 이를 활용하여 Deep Learning Classification 모델을 학습시킵니다.

하지만 이때, training data set에 없었던 펭귄, 돼지 이미지가 들어가면
모델은 학습한 class 중 고양이나 강아지로 잘못 분류하게 됩니다.
학습된 class만 분류 가능하고 학습하지 못한 class들은 낮은 확률임에도 학습한 class 중 하나로 강제 분류하려는
softmax 기반 분류 모델의 한계점 때문입니다.
이를 해결하기 위해서는 딥러닝 분류 모델이 학습하지 않은 class를 탐지하는 방법이 필요해졌고,
이에 'Open Set Recognition'이 등장하게 되었습니다.
Sol.

이렇게 Open Set Recognition이 적용되면, 앞선 예시와 달리 펭귄과 되지가 'unknown'
즉, 학습되지 않은 class라고 정확히 분류되게 됩니다.
Open Set Recognition의 특징을 알아보기 위해
우리가 주로 다루는 Closed Set Recognition과 비교를 함으로써 알아보겠습니다.

먼저, 빨간색 원인 Closed Set Recognition은 training data set의 분포와 test data set의 분포가 같습니다.
반면, 파란색 원인 Open Set Recognition은 training data set의 분포와 test data set의 분포가 다릅니다.
따라서 Open Set Recognition은 학습하지 않은,
즉 모르는 class를 모른다고 분명히 말할 줄 아는 모델을 만드는 것이 목표입니다.
지금까지의 내용에 의하면 Open Set Recognition은 기존 학습된 모델에서
분류하기 어려운 unknown class를 구분해 내는 분야를 뜻합니다.
이러한 Open Set Recognition 모델들은 먼저 known class들로 학습을 한 후,
known class와 unknown class를 가지고 평가를 진행합니다.
결국 우리는 known class를 식별하고 unknown class를 배제하여야 하므로 학습 시 known class에 관한 결정 경계를
엄격히 설정하여야하는 것이 Open Set Recognition의 목표이자 본 논문의 목표이기도 합니다.

'Recent advances in opn set recognition : A survey' 논문에 의하면 Open Set Recognition은 크게 세 분야로 나누어지고,
본 논문은 Discriminative Model 중 DNN 기반 모델이므로 이에 대한 내용을 주로 다뤄보도록 하겠습니다.
먼저, training data set의 분포와 test data set의 분포가 일치하는
DNN기반의 Closed Set Recognition부터 소개드리겠습니다.
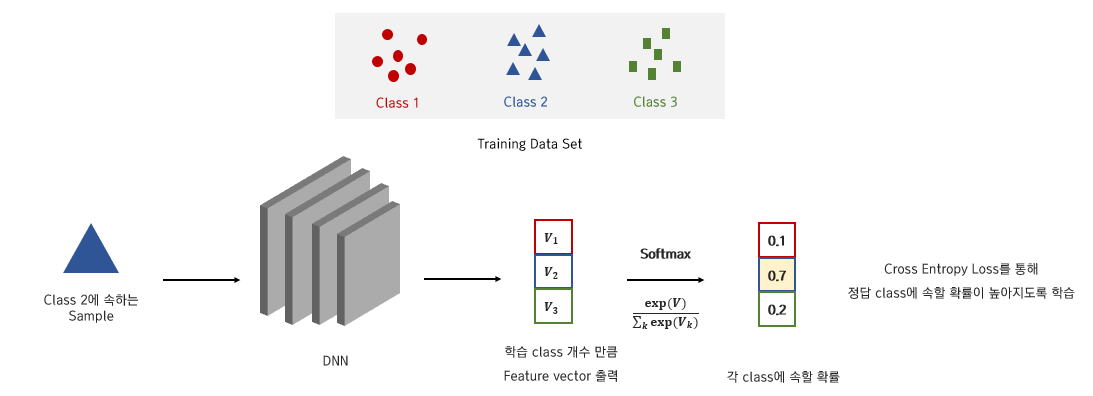
Closed Set Recognition은 학습 class 개수가 3개이므로 해당 개수만큼 feature vector가 출력되고,
feature vector에 softmax를 취함으로써 해당 입력이 각 class에 속할 확률 값이 도출되도록 합니다.
이때, cross entropy loss를 통해 입력 데이터가 정답 class에 속할 확률이 높아지도록 학습합니다.
Prob.

만약 이러한 이론을 Open Set Recognition에도 적용시키면,
해당 입력이 각 class에서 설정한 threshold 보다 확률 값이 작을 시 unknown으로 분류됩니다.
하지만 softmax activation function을 사용하여 unknown data를 분류하게 되면,
softmax 특성상 unknown data가 각 class에 속할 확률이 높게 산출되는 경향이 있어
이처럼 threshold를 설정해 unknown을 탐지하는 데에는 한계점이 존재합니다.
Sol.

따라서 이를 해결하기 위해 DNN을 기반으로 한 Open Set Recognition은
대부분 2가지 과정을 거쳐 unknown class를 unknown이라고 분류하게 됩니다.
먼저, unknown 탐지에 유용한 feature vector를 known class를 통해 학습합니다.
그렇게 학습된 모델에 새로운 data를 집어넣고 마찬가지로 feature vector를 추출한 다음,
unknown 탐지 process를 통해 unknown인지 아닌지를 분류하게 됩니다.
Related Works
위에서 설명드린 2가지 과정을 거치는 대표 알고리즘에 대해 설명드리겠습니다.
1. Open Max

첫번째는 'Open Max'라는 모델입니다.
1. 모델 학습 방법
모델을 학습할 때에는 Closed Set Recognition처럼 cross entropy loss를 사용하여 DNN 모델을 학습시킵니다.
2. unknown 탐지 방법
그렇게 학습된 모델에 정확히 예측된 training data만 사용하여 각 class의 평균 feature vector를 계산하고
각 class별 평균 feature vector와 training data들의 featrue vector를 임베딩 공간에 투영한 후,
거리 계산을 통해 극단 분포(와이블 분포)를 추정합니다.
이때, 새로운 data가 들어오면 이 data의 feature vector를 가지고 앞서 구한 각 class의 평균 feature vector와의
거리를 계산하여 각 class의 극단 분포(와이블 분포)에 대한 확률 값을 계산합니다.
이 방법론은 앞서 소개드린 softmax에 threshold를 적용한 model에 비해 새로운 data에 대해 높은 성능을 보였다고 합니다.
2. Classification-Reconstruction Learning for Open Set Recognition (CROSR)

1. 모델 학습 방법
하지만 Open Max의 경우, Cross Entropy Loss만 사용함으로써
known class 간 분류에만 집중하여 학습되기 때문에 한계가 존재합니다.
따라서 이를 극복하기 위해 복원과정에서 원본과 복원된 결과 사이의 차이를 측정한 값인
Reconstruction error를 함께 사용하여 학습시킨 CROSR이라는 모델이 등장하였습니다.
2. unknown 탐지 방법
Unknown 탐지 방법은 Open Max와 동일한 방식으로 수행됩니다.
Proposed Method
지금부터는 본 논문의 방법론을 3가지로 나누어 알아보겠습니다.
1. Sigmoid Activation 사용

Prob.
Softmax 계층은 주어진 입력 x에 대해 각 class에 속할 확률을 구하기 위해서
M개의 known class에 대한 확률 분포를 학습하게 됩니다.
그리고 이를 통해 i번째 class인 yi에 대해 아래와 같은 조건부확률 식을 생성합니다.

이때, softmax 계층은 다른 class의 logit에 비해 class yi의 logit을 증가시켜 학습하게 되면서
unknown class에 대해서도 각 class에 속할 확률을 의미하는 confidence score를 높게 부여하는 경향이 있습니다.

그렇게 되면, 물음표가 다른 class보다 검은 원 class에 가깝게 위치한다는 이유로
물음표를 검은 원 class로 결정할 가능성이 높습니다.
만약 이 물음표가 실제 원이었다면 정확히 분류해낸 것이지만,
unknown class였다면 Open Set Recognition에서는 문제가 됩니다.
Sol.
따라서 본 논문에서는 이를 해결하기 위해 Sigmoid 출력 계층을 사용하였습니다.

Sigmoid 계층은 sofmax와 달리 class yi의 logit에만 의존하는 조건부 확률을 출력하므로
개별적인 학습이 가능하다는 장점이 있습니다.
따라서 known class와 unknown class 모두 동일하게 학습되므로 둘을 구분하는 데에만 해당 계층이 활용됩니다.

즉, sigmoid 출력 계층을 사용하는 네트워크는 unknown class에 대해 softmax 출력 계층과 달리
낮은 confidence score을 부여할 수 있으므로 softmax보다 unknown class를 보다 정확히 구별할 수 있습니다.
2. Add One-vs-Rest network (OVRNs)
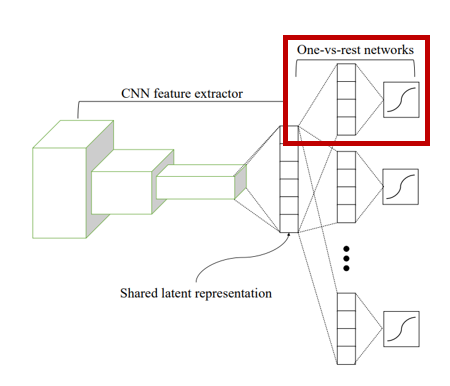
Prob.
Open Set Recognition에서는 unknown을 식별해야 하는데, 일반적인 softmax 출력 계층은
known class 중 가장 확률이 높은 class를 선택하는 경향이 있습니다.
Sol.
따라서 일반적인 softmax 출력 계층을 대체하고자 CNN(Convolutional Neural Network)의 feature extraction 뒤에
여러 개의 One-vs-Rest network(OVRN)을 추가하였습니다.
본 논문을 읽으며 OVRN이라는 이름이 붙여진 이유에 대해 생각해보았는데,
OVRN 자체가 개별 class에 대한 binary classification을 수행하는 network이므로
이러한 이름이 붙지 않았을까 생각해 보았고 실제 OVRN은 known class와 동일한 수로 존재한다고 합니다.
즉, 입력 x가 class i에 속할지 아닐지 정도만 분류하는 용도이기 때문에
softmax 출력 계층에서의 한 vector을 OVRN 모델 하나로 표현하는 것이 아닐까 싶습니다.
이처럼 OVRN은 각 class 별로 확률을 추정하기 때문에 known class에 대한 분류 성능을 유지하면서
unknown class를 거부하므로 Open Set Recognition의 성능을 향상했음을 밝히고 있습니다.
How?

OVRN은 입력 x가 class y에 속할 사후확률을 추정하기 위해 CNN의 feature extractor인 F를 통과합니다.

그 후, OVRN의 존재 목적에 걸맞게 binary cross entropy를 최소화하는 방향을 학습하게 됨으로써
unknown class를 탐지하고자 하였습니다.
3. Collective Decision of OVRNs

Prob.
보통 우리는 분류 문제를 다룰 때, 관심 있는 class에 대해서는 높은 확률 값을 얻고
나머지 class에 대해서는 낮은 확률 값을 얻고자 합니다.
하지만 OVRN의 출력 계층인 sigmoid 함수는
입력 x가 상대적으로 낮거나 높을 때 함수의 출력 값이 급격히 0 또는 1에 가까워지는 경향이 있고,
이는 곧 관심 없는 class의 확률이 0에 가까워지게 만듦으로써 분류에 어려움이 발생합니다.
Sol.
따라서 본 논문에서는 이를 해결하기 위해 OVRN의 출력 값에
logit을 취해 사후확률을 계산함으로써 확률이 0 또는 1에 근사하는 것을 방지하였습니다.
How?

먼저 본 논문이 unknown을 탐지하기 위해 제안한 Collective Decision Score은
해당 class y에 대한 logit 값에서 다른 모든 class의 logit 값의 평균을 뺀 다음 계산합니다.

그 후, 앞서 구한 score을 통해 입력 데이터를 분류할 규칙을 제안하는데
이때 Collective Decision Score가 각 class에서의 임계값보다 크면 해당 class로 분류하고
그렇지 않으면 unknownd으로 분류함으로써 DNN 분류 문제에서 주로 발생하는 과도한 일반화를 완화하고자 하였습니다.
Experiment
본 논문에서는 총 7개의 dataset(MNIST, EMNIST, Omniglot, CIFAR-10, CIFAR-100, ImageNet, LSUN)을
활용하여 연구실험을 수행하였습니다.
* MNIST : 64개의 hidden node로 구성된 단일 hidden layer OVRN을 가진 CNN을 사용하여 학습
* 나머지 : 128개의 hidden node로 구성된 단일 hidden layer OVRN을 가진 CNN을 사용하여 학습
또한, known class와 unknown class 간의 성능을 측정하기 위해 known class에서의 f1-score를 사용하였습니다.

마지막으로 Open Set Recognition에서 class imbalnace는 분류 성능에 영향을 준다고 판단하여
위와 같은 식을 가진 'openness'라는 지표를 도입하여 평가에 활용하였습니다.
* CNN feature extraction : VGGNet 사용
* Hidden layer : ReLU Activation Function 사용
* Adam optimizer, learning rate : 0.002 사용
1. Ablation study
먼저, 본 논문에서는 제안한 방법이 Open Set Recognition에 있어 얼마나 효과적인지를 판단하고자
3가지 유형의 실험을 진행하였습니다.
첫 번째는 Ablation study로 이는 본 논문에서 제안한 OVRN과 Collective Decision의 효과를 확인하기 위해
MNIST dataset을 활용한 검증 실험을 의미합니다.
MNIST dataset은 known class(0~5의 숫자)와 unknown class(6~9의 숫자)로 구성되어 있습니다.

위 히스토그램은 known class와 unknown class의 confidence score를 정규화 한 히스토그램입니다.
그리고 이를 통해 softmax를 활용한 모델, sigmoid를 활용한 모델, OVRN을 활용한 모델들을 비교하고자 하였습니다.
결과적으로는 본 논문에서 제안한 CNN-OVRN이 가장 분리된 히스토그램을 제공함으로써
known class와 unknown class를 가장 잘 구분했음을 알 수 있습니다.

또한, 다른 6개의 모델들과도 비교를 하였는데 총 2가지의 dataset을 가지고 실험을 진행하였으며,
이와 동시에 'openness'도 변화시켜 가며 진행하였습니다.
앞서 보여드린 'openness' 수식에 의하면 openness는 증가할수록 unknown class의 수가 더 많아지게 되는데,
이는 분류 모델에게 더 많은 class를 구분하고 인식해야 하는 어려움을 줄 수 있으므로
f1-score이 일반적으로는 감소하는 경향을 보입니다.
하지만 제안된 OVRN과 Collective Decision을 사용한 모델은 견고한 결과를 도출하고 있음을 볼 수 있습니다.
2. Sensitivity Analysis
Sensitivity Analysis(민감도 분석)란 어떤 모델이 변수의 변화에 얼마나 민감하게 반응하는지를 뜻하며
이를 통해 변수의 변화가 모델의 성능에 어떠한 영향을 미치는지를 판단할 수 있습니다.
따라서 본 논문에서는 OVRN의 성능에 영향을 미치는 요소인
hidden layer와 hidden node의 수에 대해 Sensitivity Analysis를 수행하였습니다.

위 그림을 보시면 hidden node의 수가 8개 이상부터는 node를 아무리 추가하더라도 성능 향상 크지 않으며
hidden layer도 마찬가지로 layer 추가가 성능 향상에 많은 영향을 미치지 않음을 확인할 수 있습니다.
이는 OVRN이 복잡한 구조나 많은 수의 hidden node를 필요로 하지 않고도 원하는 작업이 가능함을 뜻합니다.
3. Comparison with State-of-the Art Methods
마지막으로 본 논문은 Open Set Recognition의 SOTA 모델들과 비교 실험을 진행하였습니다.

본 논문에서는 training data set으로 MNIST와 CIFRAR-10을 활용하였고,
test 시에는 다른 dataset을 unknown class로 추가하였으며 이는 아래와 같습니다.
* MNIST : Omniglot, Noise, MNIST-noise를 unknown class로 사용
* CIFAR-10 : ImageNet, LSUN을 unknown class로 사용

이렇게 두 가지 data set을 통한 비교 실험 결과를 보았을 때,
본 논문에서 제안한 방법이 다른 SOTA 모델들보다 더 좋은 성능을 보임을 알 수 있습니다.
Conclusion
최종적으로 본 논문은 기존 분류 문제와 softmax 계층 활용의 한계점을 극복하고자
CNN 뒤에 여러 개의 OVRN을 추가하였고, 이 OVRN의 결정을 결합하는 Collective Decision 방법을 제안하였습니다.
이를 통해 각 class 별로 feature을 학습하고 결정경계를 강화함으로써
Open Set Recognition이 가지고 있던 일반화 문제를 극복하였음이 본 논문의 장점이라고 생각하며,
무엇보다 비교적 간단한 모델을 구성하고 있음에도
다른 Open Set Recognition의 SOTA 모델들에 비해 높은 성능을 보이는 것이 큰 강점이라고 생각합니다.



