
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- LinearRegression
- 시계열 데이터
- 데이터전처리
- Python
- machinelearning
- 시계열데이터
- 손실함수
- OrdinalEncoder
- DataScience
- 선형회귀분석
- 다중선형회귀분석
- 의사결정나무
- 결정계수
- 비지도학습
- dataframe
- 잔차분석
- 지도학습
- RegressionTree
- LogisticRegression
- ML
- 단순선형회귀분석
- 하이퍼파라미터
- scikitlearn
- time series
- 딥러닝
- deeplearning
- GridSearchCV
- 데이터분석
- 로지스틱회귀분석
- 분류
- Today
- Total
IE가 어른이 되기까지
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 본문
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
기모랑의 초코 2023. 9. 20. 14:27

오늘 다뤄볼 논문은 'Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks'라는 논문입니다.
Introduction
본 논문에서는 Model-Agnostic한 상황에서 적용할 수 있는 Meta-Learning 알고리즘을 제안했는데,
Model-Agnostic과 Meta-Learning이란 무엇일까요 ?
Model-Agnostic
Model-Agnostic이란 모델에 대한 제약 없이 적용가능하다는 의미입니다.
Meta-Learning
다음으로 Meta-Learning이라는 것이 무엇이고, 왜 등장하게 되었는지에 대해 알아보겠습니다.
사람은 적은 수의 예시를 보고도 정확한 판단이 가능하고
단 몇 분만의 경험으로도 새로운 기술을 금방 익힐 수 있습니다.
반면 기계는 이렇게 적은 정보만을 가지고 학습하면
이전의 경험에 의존하게 되어 overfitting이 발생하게 됩니다.
또한, 이전 경험과 새로운 data의 형태는 작업에 따라 다를 수 있으므로 유연한 학습이 불가능하다는 문제점이 있습니다.
그렇게 Meta-Learning이라는 개념이 등장하게 되었습니다.

따라서 Meta-Learning은 위 문제점들을 해결하기 위해 적은 수의 데이터셋 및 training 반복만 사용하고도
새로운 task에 빠르게 적응할 수 있는 모델을 훈련시키는 것이 목적입니다.
그렇기 때문에 적은 data 양과 부족한 computational power에서도 좋은 성능을 보인다는 장점이 있습니다.
이러한 Meta-Learning은 Learning to Learn이라고도 표현하는데요,
이는 이전 경험으로부터 새로운 task를 스스로 학습하는 방법론을 의미합니다.

이러한 Meta-Learning은 크게 Model-based model, Metric-based model,
Optimization-based Approach로 나눌 수 있습니다.
1. Model-based Model
이는 모델의 내부나 외부에 memory를 둠으로써 학습 속도를 조절하는 방법으로
모델은 몇 번의 training step만으로도 파라미터를 빠르게 찾는 것이 가능해집니다.
관련 연구 : Prototype Network, Matching Network 등
2. Metric-based Approach
Metric-based Approach 방법론은 Training data를 저차원 공간에 임베딩한 후,
새로운 데이터가 들어오면 마찬가지로 저차원 공간에 임베딩하여
가장 가까운 클래스로 분류하는 방법론입니다.
관련 연구 : Memory Network, NTM, MANN 등
3. Optimization-based Approach
이는 각 task의 최적의 파라미터를 구할 수 있게 하는
초기 파라미터를 최적화하는 방법론으로 본 논문은 세번째에 해당됩니다.
관련 연구 : MAML, Reptile 등
Related Works
우리도 잘 알고 있다시피 Training data가 적은 상황에서는
Deep Learning 모델 구축 자체가 어렵습니다.
이에 사람처럼 몇 장의 사진만을 보고도 직관적으로 판단할 수 있는 모델을 만들기 위해
소량의 data, 즉 few-shot 만으로도 뛰어난 학습을 하는 few-shot learning이 등장하게 되었습니다.

앞서 설명 드린 Meta-Learning도 few-shot learning 중 하나입니다.
그렇다면 Transfer Learning은 무엇일까요 ?
Transfer Learning

Transfer Learning이란 대량의 데이터로 Pre-trained 모델을 생성한 다음,
적은 데이터셋을 Fine-tuning하는 알고리즘입니다.
그렇기 때문에 Meta-Learning보다는 조금 더 많은 데이터셋이 필요합니다.
Proposed Method

본 논문에서 제안한 Model-Agnostic Meta-Learning(MAML)은
소량의 data를 기반으로 다수의 task를 빠르게 학습하는 알고리즘인 Meta-Learning으로서의 특징과
Gradient Descent를 사용하여 학습하는 모든 모델들과 호환 가능하다는 Model-Agnostic한 특징을
가지고 있는 방법론이라고 할 수 있겠습니다.
Key Idea
본 논문에서는 MAML의 핵심 아이디어 세 가지를 강조하고 있습니다.
1)
먼저 MAML은 Meta-Learning을 통해 모델이 빠르게 새로운 task에 적응할 수 있도록
모델의 초기 파라미터를 최적화하는 방법론인데, 이 최적화 과정에서 MAML은 Gradient Descent를 활용하였습니다.
2)
또한, 모델의 초기 파라미터를 적은 양의 data(few-shot)와 몇 번의 업데이트 만으로도
새로운 task에서 최대한의 성능을 발휘하고자 하였습니다.
3)
마지막으로 모델 아키텍처에 제한을 두지 않았고 파라미터를 늘리지 않았다는 점이 MAML의 핵심 아이디어입니다.
즉, MAML은 모델에 대한 제약 없이 새로운 task에 빠르게 적응할 수 있는
Gradient 기반의 학습을 진행하는 방법론이라고 할 수 있겠습니다.
Meta-Learning Problem Set-up
MAML에는 2가지 구성요소가 존재합니다.
구성요소 1)

첫번째는 input은 x, output은 a인 모델 f입니다.


두번째는 task(과제)인데, 이는 모델 f가 학습하고 적응해야 하는 개별 작업을 나타냅니다.
따라서 회귀냐, 분류냐, 강화학습이냐에 따라 input과 output 등이 달라집니다.
이러한 task는 총 4가지 주요 항목으로 이루어져 있습니다.
1)

첫번째는 각 task 별 피드백을 제공하는 손실함수로
모델 f는 이를 최소화하려고 합니다.
2)

두번째는 task가 시작될 때 첫번째 관측인 x1의 확률분포로
모델이 task를 시작할 때 어떤 초기 상태로 시작하는지에 대한 정보를 포함하고 있습니다.
3)

세번째는 현재 관측 xt와 액션 at를 사용하여 다음 관측 xt+1의 확률분포를 정의한 것으로
모델이 어떻게 작동하는지에 대한 정보를 포함하고 있어
이를 통해 새로운 task에서도 어떻게 행동해야 하는지 빠르게 학습할 수 있습니다.
4)

마지막 H는 task의 시간제한으로
모델은 이 시간 내에 task를 수행하고 손실함수를 최소화하고자 합니다.
우리가 하고자 하는 Meta-Learning의 목적은
적은 update 만으로 각 task별 파라미터를 구할 수 있는 최적의 초기 파라미터를 찾는 것입니다.
아래 다이어그램으로 MAML이 Meta-Learning에서
새로운 task에 대해 초기 파라미터를 어떻게 학습하는지 알 수 있습니다.


새로운 task가 총 3개가 있다고 가정했을 때,
그림을 통해 초기 파라미터가 학습되는 방향을 보시면
초기 파라미터가 가리키는 방향이 task 1,2,3에 대해 최적은 아니지만
이후 task 1,2,3을 빠르게 adaptation 할 수 있는 방향으로 학습하고 있음을 알 수 있습니다.
즉, 초기 파라미터가 특정 task에 대해 최적의 파라미터가 아니더라도
gradient를 통해 각 task에 빠르게 adaptation할 수 있는 파라미터로 업데이트되며
이렇게 업데이트된 파라미터를 기반으로 각 task에 대한 최적의 모델 파라미터를 찾아가는 것이
MAML의 핵심 아이디어입니다.
A Model-Agnostic Meta-Learning Algorithm
지금부터는 앞선 다이어그램을 바탕으로 MAML에 대한 수도 코드에 대해 살펴보겠습니다.


1. 먼저, 초기 파라미터를 무작위로 초기화 시킵니다.
3. 또한, 새로운 task인 Ti를 전체 task set인 p(T)에서 랜덤하게 샘플링 합니다.
5. 그 후, 모든 task Ti의 K개의 샘플에 대해 모델 f를 사용하여 손실함수에 대한 gradient를 계산합니다.
6. 마지막으로 앞에서 살펴본 다이어그램처럼 Gradient Descent를 사용하여 adaptation된 파라미터 계산을 수행합니다.
[Adaptation]

8. 각 task에 대한 계산이 완료되었으면 확률적 경사 하강법을 통해 모든 task에 대한 손실함수의 gradient를 더하고
학습률 베타를 사용하여 모델의 초기 파라미터를 업데이트 합니다.
[Meta-Learning]


이때, MAML은 개별 task에서 계산된 Loss의 합을 최소화하는 방향으로 파라미터를 최적화합니다.
본 논문에서는 MAML를 지도학습과 강화학습 문제에 대입해보았는데,
알고리즘은 앞서 소개드린 것과 동일합니다.
Species of MAML - Supervised Regression and Classification



회귀 문제를 풀기 위해서는 손실함수로서 MSE(Equation(2))를 사용하였고,
분류 문제에 대해서는 손실함수로서 Cross-Entropy(Equation(3))를 사용하였습니다.
Species of MAML - Reinforcement-Learning


강화학습에서의 Few-shot Meta-Learning의 목표는
agent가 test setting에서 적은 수의 experience 만을 사용하더라도
새로운 test task에 대한 policy를 빨리 획득할 수 있게 만드는 것으로
예를 들자면 하나의 미로에 특화된 알고리즘이 다른 미로 탐색에 활용될 수 있다는 의미를 뜻합니다.
수식 4는 강화학습에 대한 손실함수이며 Reward 변수가 추가된 것 외로는 지도학습과 동일합니다.
Experiment
실험 목표
본 논문에서는 아래 세가지에 대한 답을 얻는 목적으로 실험을 진행하였습니다.
1. MAML이 새로운 task를 빠르게 학습할 수 있는가 ?
2. MAML이 여러 도메인에 적용될 수 있는가 ? (Regression, Classification, Reinforcement-Learning 등)
3. MAML로 학습된 모델이 gradient update를 계속할 때 더 개선되는가 ?
1. Regression task
먼저, 회귀에서는 NN모델을 사용하였고 데이터를 각각 5개, 10개 사용한
2번의 실험을 통해 sin 함수를 예측하고자 하였습니다.
이때, Few-shot adaptation에 대한 결과를 비교하고자
MAML을 적용한 방식(왼쪽 그림)과 Meta-learning을 사용하지 않은 pretrained된 모델(오른쪽 그림)을 사용하였습니다.


MAML 모델의 경우 업데이트 이전에는 pretrained 모델과 유사하게 예측하지만
업데이트 이후에는 적은 데이터로도 ground truth와 상당히 유사한 결과를 나타냄을 알 수 있습니다.
또한, 보라색 data가 일부 구간에만 몰려 있음에도 불구하고
MAML은 data가 없는 구간도 잘 예측하고 있는 것을 볼 수 있습니다.
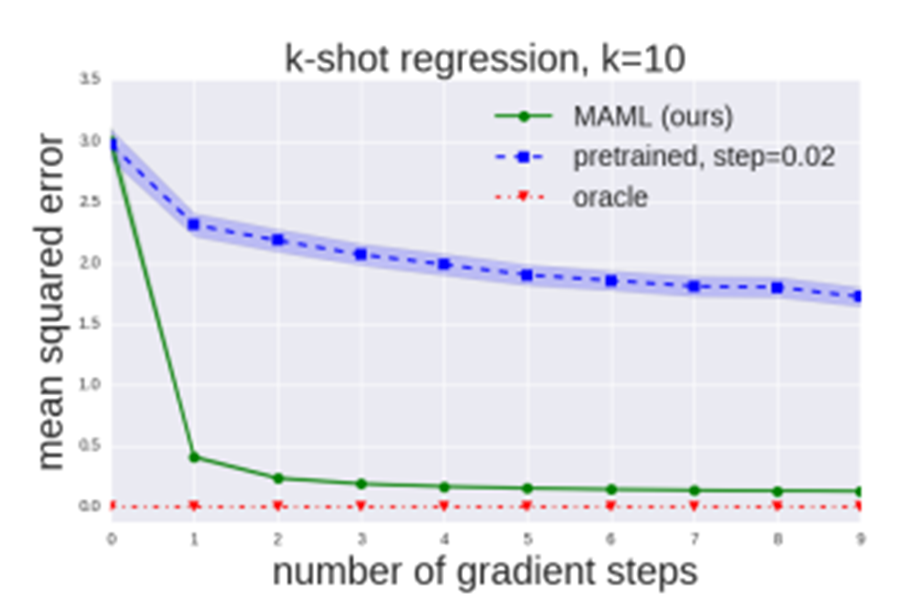
또한, MAML의 Learning curve를 보시면 gradient step이 늘어나면서
파라미터에 대해 overfitting 되지 않고 계속 향상되고 있음을 알 수 있습니다.
2. Classification task
다음은 분류 문제로 해당 과제에서는 두가지 데이터(Omniglot, Minilmagenet)를 사용하였습니다.

이때, 비교를 위해 다른 Meta-Learning 방법인 Siamese networks와 Matching networks등을 이용하였는데,
MAML이 더 적은 parameter를 사용했음에도 Matching networks와 Meta-Learner LSTM보다
더 좋은 성능을 보인 것을 알 수 있습니다.
3. Reinforcement task
마지막은 강화학습으로 이는 총 2가지 실험을 진행했습니다.
1) 2D Navigation
첫번째 실험은 Agent가 2D 공간에서 목표 위치로 이동해야 하는 실험으로
이때 각 task에서의 목표 위치(goal position) 및 초기 위치는 무작위로 선택됩니다.

아래 그림을 보시면 MAML은 pretrained과 달리 새로운 task에 대한 적응을 매우 빨리 수행하고 있음을 알 수 있고
위 그림을 보시면 단 한번의 gradient update만으로도 높은 성능을 달성함을 확인할 수 있습니다.
2) Locomotion
두번째 실험은 MuJoCo라는 시뮬레이터를 사용하여 고차원 이동 작업을 수행한 실험으로
이때 두가지 시뮬레이션 로봇(half-cheetah, ant)이 사용됩니다.
실험에는 목표 속도(goal velocity) 및 이동방향(forward/backward)에 따라 agent가 움직이는 task가 포함되는데
각 task에서 목표 속도(goal velocity) 및 이동방향(forward/backward)은 무작위로 선택됩니다.

실험 결과, MAML은 단일 gradient update로도 agent의 속도 및 이동 방향을 효과적으로 적응하며
더 많은 gradient step을 거칠수록 성능이 더욱 향상됨을 알 수 있습니다.
Conclusion
본 논문은 gradient descent를 통해 적은 data 양, update 수를 가지고
최적의 모델의 초기파라미터를 학습하는 Meta-Learning 방법론을 제안하였습니다.
즉, 다양한 task에 쉽고 빠르게 적응할 수 있는 초기 파라미터를 gradient update를 통해 찾아내겠다는 것이 핵심입니다.
MAML은 gradient descent가 가능한 회귀, 분류, 강화학습을 포함한 모든 모델과 사용 가능하고,
간단하며 파라미터를 더 추가하지 않아도 된다는 장점이 존재합니다.



